Обучение гибрида LLM и рекомендательной системы на Semantic IDs
TL;DR: Обучил языковую модель Qwen3-8B работать с семантическими ID вместо обычных хешей. Модель стала “билингвальной” — понимает и естественный язык, и идентификаторы товаров. Результат: можно управлять рекомендациями через чат, получать объяснения и даже генерировать названия для бандлов продуктов.
Идея Semantic IDs меня сразу зацепила. Вместо случайных хеш-идентификаторов для видео, песен или товаров можно использовать семантически осмысленные токены, которые LLM понимает нативно. Возник вопрос: можно ли обучить гибрид LLM и рекомендательной системы на богатых поведенческих данных, которые делают современные рекоммендеры такими эффективными?
Оказалось, можно! Результат — языковая модель, которая говорит и на английском, и на ID товаров, не через retrieval или другие инструменты, а как единая “билингвальная” модель, где товары (семантические ID) — часть её словаря. Как рекоммендер, она может рекомендовать товары по истории взаимодействий. Но главный сюрприз и прорыв — возможность просто общаться с моделью, чтобы направлять её рекомендации, получать рассуждения о выборе, объяснения и даже креативные названия для наборов продуктов.
Код для подготовки данных, обучения модели и чата с ней. (Примечание: это небольшая модель с базовым fine-tuning, поэтому промпты очень важны. Также она не такая универсальная и надёжная, как большинство LLM, из-за ограниченного дообучения.)
Зачем это нужно?
Это объединяет лучшее из рекоммендеров и языкового моделирования. С одной стороны, языковые модели обладают знаниями о мире и могут красноречиво говорить о продуктах, но не знают наш каталог. Их рекомендации общие и страдают от популярности. С другой стороны, модели поиска и рекомендаций обучены на нашем каталоге и миллиардах взаимодействий пользователей. Они отлично предсказывают, что пользователь кликнет или купит дальше, но их нельзя направлять через естественный язык или получать рассуждения о выборе. (Что у них общего — обучение на последовательностях.)
Для этого мы сначала расширяем словарь языковой модели токенами семантических ID вроде <|sid_0|>, <|sid_1|>, <|sid_2|> и так далее. Эти токены представляют каталог. Затем применяем continued pretraining, чтобы научить модель отношениям между семантическими ID и каталогом, и дальше дообучаем на последовательностях поведения пользователей. Вместе это учит модель делать рекомендации — из нашего каталога — на основе предпочтений пользователей.
Хотя этот гибрид LLM-рекоммендер может не дотягивать до точности специализированного многоэтапного рекоммендера, он даёт новую возможность: управляемость и рассуждения о рекомендациях. Результат — единый опыт для поиска, рекомендаций и чата, позволяющий пользователям находить нужное в каталоге, просто спросив об этом.
Пользователь: Мне нравятся игры про животных и милые.
<|rec|>Модель интерпретирует запрос на естественном языке (“животные и милые”) и генерирует семантические ID для релевантных игр.
<|sid_start|><|sid_173|><|sid_324|><|sid_764|><|sid_768|><|sid_end|>, <|sid_start|><|sid_201|><|sid_397|><|sid_701|><|sid_768|><|sid_end|>, <|sid_start|><|sid_173|><|sid_305|><|sid_670|><|sid_768|><|sid_end|>Ассистент: “Animal Crossing: New Leaf”, “DISNEY INFINITY Starter Pack 3DS”, “Nintendogs + Cats: Golden Retriever and New Friends”
Данные и модели
Поиск обучающих данных с метаданными товаров и последовательностями пользователей
Используем данные из категории Video Games датасета Amazon Reviews 2023 (Hou et al., 2024). В данных есть богатые метаданные продуктов, и мы можем создать последовательности взаимодействий пользователей.
Датасет содержит 137k товаров, каждый с полями: название, описание, характеристики, категория, информация о магазине, рейтинги, цены и т.д. После оставления только товаров с названиями длиннее 20 символов и описаниями длиннее 100 символов остаётся 66k товаров. Поведенческие данные содержат 737k записей. Из них я построил 79k последовательностей покупок пользователей, каждая содержит минимум три валидных товара. Средняя длина последовательностей — 6.5 товаров.
Также рассматривал данные Amazon KDD Cup 2023 (Amazon, 2023). Там было 500k товаров и фокус на последовательных поведенческих данных. Однако многоязычность добавляла сложности, а отсутствие поля категории продукта усложняло работу. В итоге выбрал датасет Amazon Reviews для простоты и экономии вычислительного бюджета.
Semantic IDs из RQ-VAEs
Semantic IDs (Rajput et al., 2023; Singh et al., 2023) — это иерархические представления, которые кодируют товары в последовательность токенов, заменяя эмбеддинги или ID на основе хешей. В отличие от обычного ID товара (B0040JHNQG), который не имеет смысла, семантический ID (<|sid_0|><|sid_256|><|sid_512|><|sid_768|>) кодирует информацию о товаре. В результате обучения похожие товары естественно делят общие префиксы, формируя древовидную структуру, где каждый уровень ID представляет всё более детальную информацию о товаре.
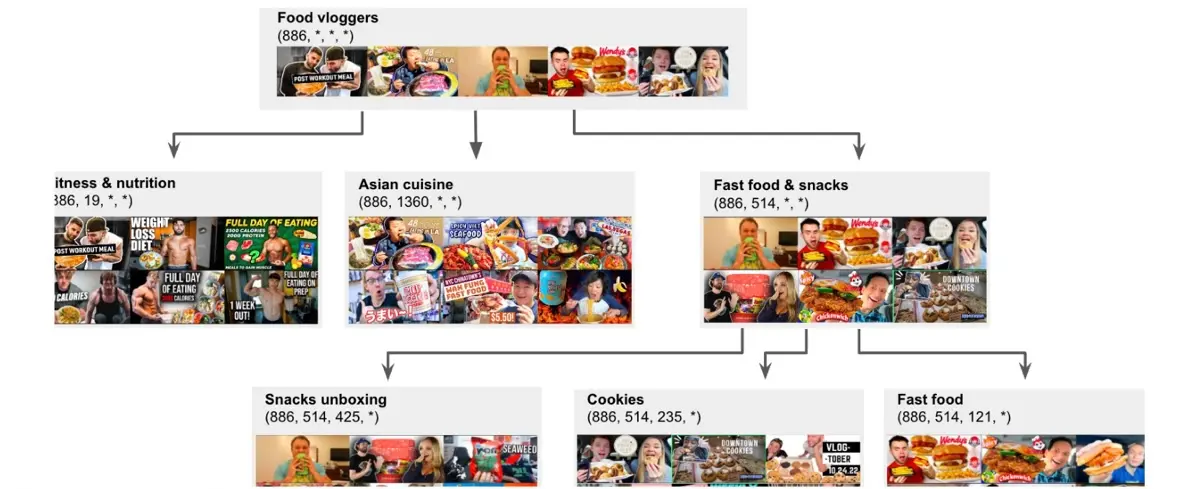
Иерархическая структура семантических ID для видео о еде (источник)
Residual Quantized Variational Autoencoders (RQ-VAEs; Zeghidour et al., 2021, Lee et al., 2022) — то, что мы используем для преобразования непрерывных эмбеддингов в дискретные семантические ID. Начинаем с кодирования метаданных товара (например, название, описание) в эмбеддинг. Затем RQ-VAE использует иерархическую квантизацию для преобразования этого эмбеддинга в последовательность дискретных токенов.
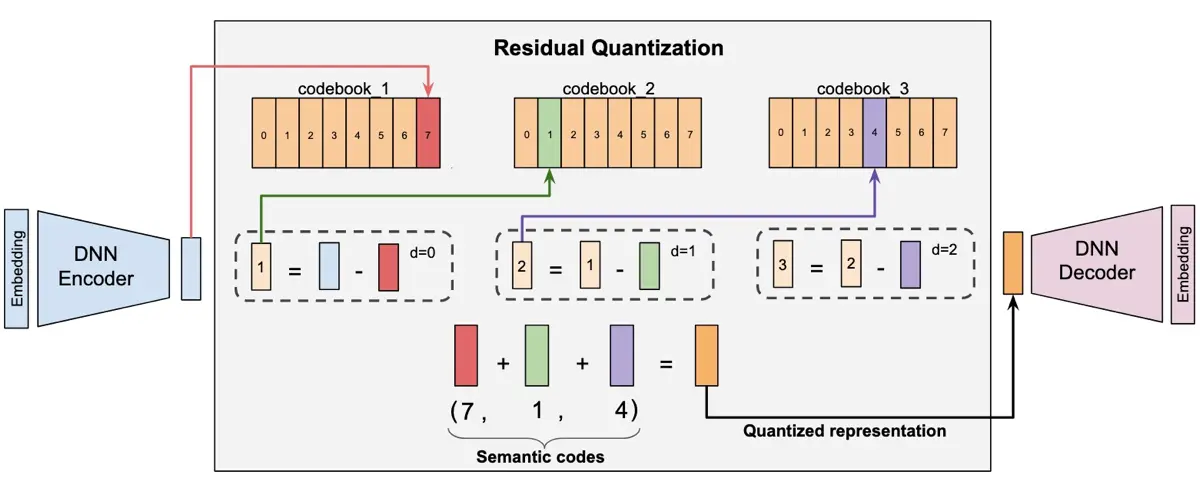
Как RQVAEs преобразуют эмбеддинги в семантические ID (источник)
Это итеративный процесс. На первом уровне модель находит ближайший вектор в первом кодовом словаре к входному эмбеддингу; этот вектор становится первым токеном Semantic ID. Модель вычисляет ошибку квантизации, или остаток, вычитая выбранный вектор кодового словаря из входного эмбеддинга. На втором уровне она находит ближайший вектор во втором кодовом словаре к этому остатку, что даёт второй токен. Процесс повторяется для каждого уровня, каждый шаг захватывает всё более тонкие детали, которые пропустили предыдущие уровни.
Функция потерь RQ-VAE стоит обсуждения, так как её понимание — ключ к генерации качественных семантических ID. Общая функция потерь имеет два основных компонента:
Первый компонент, потеря реконструкции, гарантирует, что декодер может точно восстановить исходный эмбеддинг товара () из финального квантизованного представления (). Это стандартная квадратичная ошибка:
Второй компонент, потеря квантизации, измеряет, насколько хорошо векторы кодового словаря соответствуют остаткам, сгенерированным энкодером. Он содержит два слагаемых:
Первое слагаемое (), потеря кодового словаря, отвечает за обучение эмбеддингов кодового словаря. Оно измеряет расстояние между остатком энкодера () и выбранным вектором кодового словаря (). Stop-gradient применяется к выходу энкодера (), чтобы рассматривать остатки как фиксированную цель. Таким образом, градиенты идут только к вектору кодового словаря, приближая его к выходу энкодера.
Второе слагаемое (), потеря приверженности, отвечает за обучение энкодера. Оно измеряет то же расстояние, но stop-gradient применяется к вектору кодового словаря () вместо этого. Это останавливает обновления кодового словаря и заставляет энкодер производить выходы, или приверженность к векторам, которые уже есть в кодовом словаре. Гиперпараметр контролирует силу этого штрафа приверженности.
# PyTorch код для функции потерь (без рекурсивного цикла)
reconstruction_loss = F.mse_loss(x, x_reconstructed)
codebook_loss = F.mse_loss(residual.detach(), codebook_vector)
commitment_loss = F.mse_loss(residual, codebook_vector.detach())
quantization_loss = codebook_loss + commitment_weight * commitment_loss
total_loss = recon_loss + quantization_lossЧерез этот процесс RQ-VAE производит семантический ID как последовательность токенов, по одному с каждого уровня квантизации. Поскольку похожие товары делят общие префиксы, языковые модели могут лучше понимать отношения между продуктами, что также полезно для древовидного поиска.
# Как иерархически кодировать эмбеддинги в семантические ID
def encode_to_semantic_ids(self, x: Tensor) -> Tensor:
with torch.no_grad():
residual = self.encode(x)
indices_list = []
for vq_layer in self.vq_layers:
vq_output = vq_layer(residual)
indices_list.append(vq_output.indices)
residual = residual - vq_output.quantized
return torch.stack(indices_list, dim=-1)Однако практическая проблема — это не гарантирует уникальный ID для каждого товара. В моих экспериментах с трёхуровневым кодовым словарём, где каждый уровень имеет 256 кодов, мы видели коллизии на ~10% из 66k товаров. Чтобы решить это, я добавил четвёртый уровень, где приписываю последовательно увеличивающийся токен к каждому ID, чтобы гарантировать уникальную идентификацию каждого продукта.
SASRec, Qwen3-Embedding-0.6B и Qwen3-8b
Помимо RQ-VAE, мы используем ещё три модели. Сначала обучим SASRec на семантических ID, чтобы валидировать их качество и сравнить с базовой линией SASRec на обычных ID товаров. Затем используем модель Qwen3-Embedding-0.6B для кодирования метаданных продуктов в эмбеддинги. Наконец, дообучим модель Qwen3-8B, чтобы она понимала и рекомендовала товары через семантические ID.
SASRec (Kang & McAuley, 2018) — последовательный рекоммендер, вдохновлённый архитектурой Transformer. Он кодирует историю взаимодействий пользователя и использует механизм self-attention, чтобы взвешивать наиболее релевантные прошлые товары для предсказания следующего. Это позволяет модели изучать долгосрочные зависимости в поведении пользователей и превосходить старые рекуррентные модели вроде RNN и GRU, будучи более эффективной благодаря параллелизуемости.
Qwen3-Embedding-0.6B (Zhang et al., 2025) — часть серии моделей эмбеддингов доступных в размерах 0.6B, 4B и 8B. Они обучены через многоэтапный процесс, включающий предобучение на синтетических данных, затем supervised fine-tuning и слияние моделей для робастности. Модель 8B достигает SOTA производительности на бенчмарке MTEB Multilingual.
Qwen3-8B (Yang et al., 2025) — плотная языковая модель из семейства Qwen3. Несмотря на то, что это одна из меньших моделей, её пост-обучение оптимизировано через strong-to-weak дистилляцию на Qwen3-235B-A22B и Qwen3-32B. Это делает Qwen3-8B относительно способной для своего размера, превосходя более крупные модели предыдущего поколения вроде Qwen2.5-14B более чем на половине оцениваемых бенчмарков, особенно STEM и кодирование. Как и другие модели в серии Qwen3, Qwen3-8B имеет двойные режимы thinking и non-thinking.
Очистка данных и создание последовательностей пользователей
Сначала подготавливаем метаданные товаров для обеспечения качественных входов для модели семантических ID. Начинаем с исключения товаров с названиями короче 20 символов или описаниями короче 100 символов. Это сократило количество товаров вдвое, с 137k до 66k уникальных товаров.
Затем очищаем описания товаров с помощью Gemini 2.5 Flash Lite (Comanici et al., 2025), исправляя обрезанные предложения, удаляя HTML и уменьшая многословие. Это сократило среднюю длину описания вдвое, с 1,038 до 538 символов. Аналогично удаляем рекламный текст и стандартизируем форматирование названий, превращая многословные листинги вроде “NEW! LIMITED! Sega Saturn RGB SCART LEAD CABLE…” в чистое “Sega Saturn RGB SCART Cable”.
Затем обогащаем данные, извлекая структурированные метаданные, такие как тип продукта (Game, Hardware, Accessory), платформа (PS4, Xbox, Wii), жанр (Roguelike, Soulslike, Metroidvania), тип железа, бренд, режимы мультиплеера и т.д. Этот процесс имел 98% покрытие для информации о платформе, 78% для идентификации бренда и 51% для классификации жанра.
Наконец, для построения последовательностей пользователей дедуплицируем по пользователям и строим истории взаимодействий, получая 91.5k последовательностей. Из этих последовательностей исключаем товары без метаданных, затем фильтруем последовательности с менее чем тремя товарами. Также обрезаем последовательности до максимальной длины 100 товаров (только 28 последовательностей были обрезаны). Это дало датасет из 78.6k последовательностей со средней длиной 5 товаров и средним арифметическим 6.5 товаров.
Обучение RQ-VAE для генерации Semantic IDs
Для эмбеддинга товаров используем модель Qwen3-Embedding-0.6B. Она поддерживает кастомизацию входной инструкции для различных задач, и мы добавляем префикс “Given a product description, generate a semantic embedding that captures its key features and characteristics”. Из этого получаем 1024-мерные эмбеддинги через last token pooling и L2-нормализуем их перед сохранением.
RQ-VAE состоит из энкодера, трёх уровней квантизации с 256 кодами каждый и симметричного декодера. Для стабильности обучения используем rotation trick (Fifty et al., 2025) как замену Straight-Through Estimator (для вычисления градиента ). Другие оптимизации включали инициализацию кодовых словарей через k-means кластеризацию, сброс неиспользуемых кодов и использование большого размера батча. Также пробовал несколько техник, которые не помогли, такие как обновление кодового словаря через EMA и остановка градиентов к декодеру.
Обученный RQ-VAE достиг 89% уникальных семантических ID на 66k товарах на трёх уровнях квантизации. Для разрешения оставшихся коллизий я добавил четвёртый токен, который присваивает уникальный последовательный ID (0, 1, 2, …) любым товарам, которые делят те же первые три кода. Это гарантирует, что каждый товар имеет уникальный 4-частный семантический ID.
Я провёл несколько десятков экспериментов, чтобы понять больше о RQ-VAEs и их выходных семантических ID, и найти оптимальную конфигурацию для модели. Вот ключевые находки.
Сначала экспериментировал с весом приверженности , который балансирует точность реконструкции и приверженность кодовому словарю. Тестировал значения 0.25 (жёлтый), 0.5 (оранжевый) и 1.0 (красный), и обнаружил, что более высокий 1.0 привёл к наибольшему количеству уникальных ID, но также имел самую высокую валидационную потерю. И хотя более низкий 0.25 привёл к немного большему количеству уникальных ID, 0.5 имел самую низкую валидационную потерю. Таким образом, на этом датасете я обучил последующие RQ-VAEs с = 0.5. (Примечание: это отличается от статей о Semantic ID, которые использовали = 0.25.)
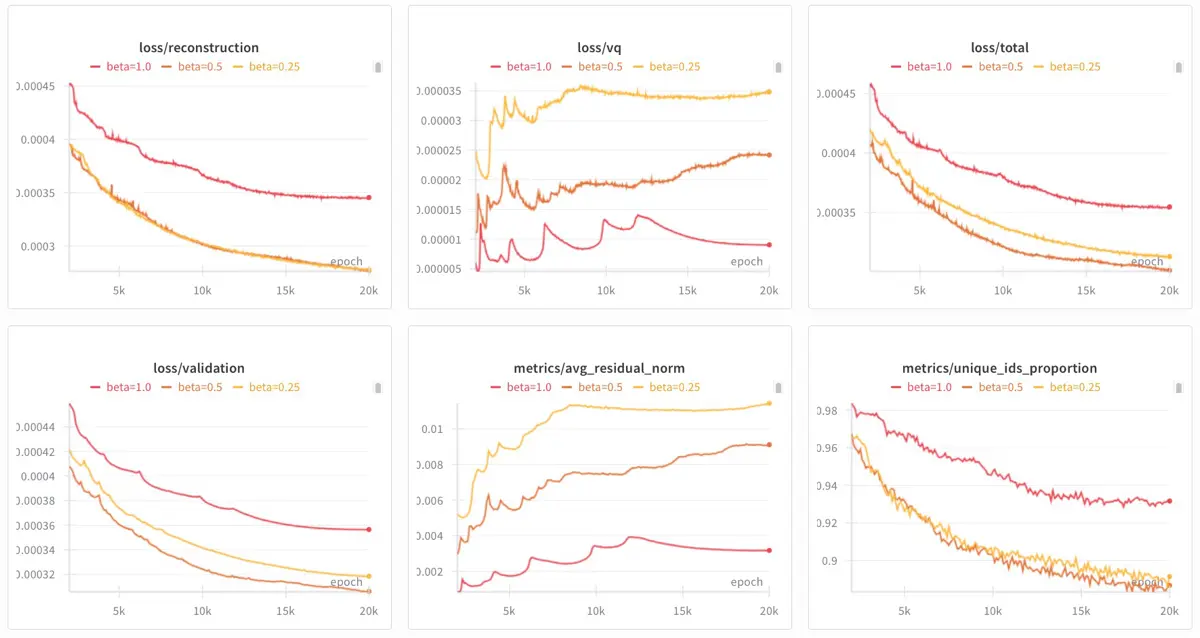
Кривые с beta = 0.25 (жёлтый), 0.5 (оранжевый) и 1.0 (красный)
Также экспериментировал с более мелким энкодером и влиянием очистки метаданных. Более мелкий энкодер (зелёный) показал худшие результаты, увеличив валидационную потерю и сократив количество уникальных ID. Однако инвестиции в очистку данных окупились (синий). Это привело к модели с самыми низкими потерями реконструкции и валидации, имея при этом самую высокую долю уникальных ID. Я использовал RQ-VAE из этого запуска.
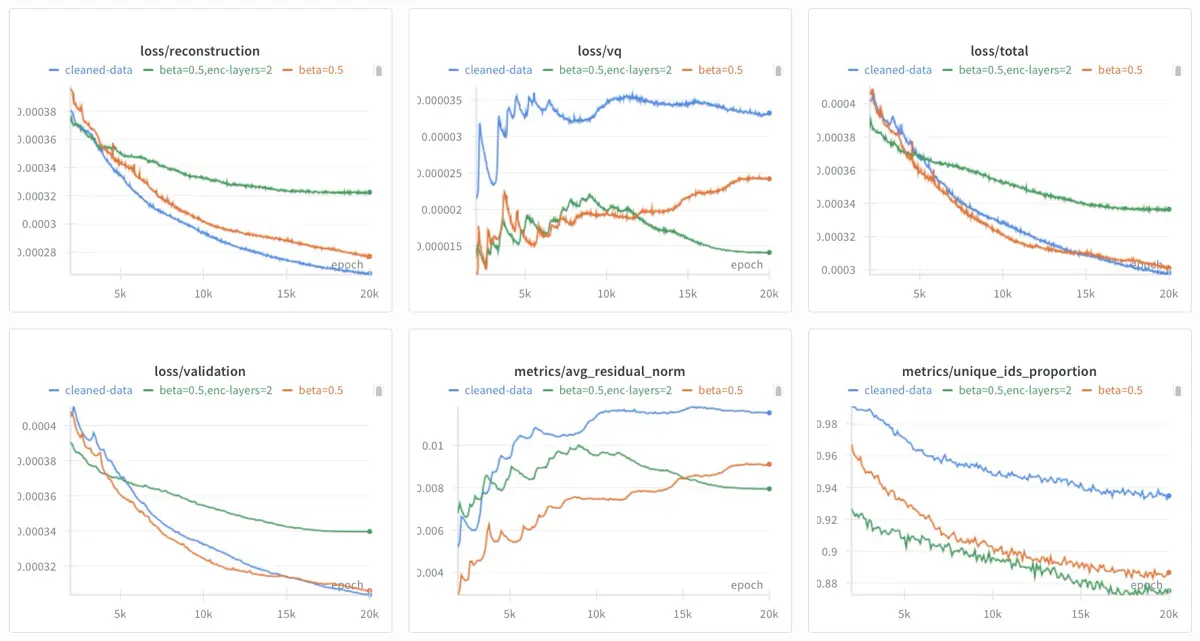
Кривые с beta = 0.5 (оранжевый), более мелкий энкодер (зелёный) и очищенные данные (синий)
Ещё один способ оценить RQ-VAEs — проверить использование кодового словаря. Относительно равномерное использование по всем кодам предполагает, что модель использует свою полную выразительную способность. Финальный RQ-VAE демонстрирует это хорошо; на всех трёх уровнях квантизации использование распределено равномерно с низкой дисперсией.
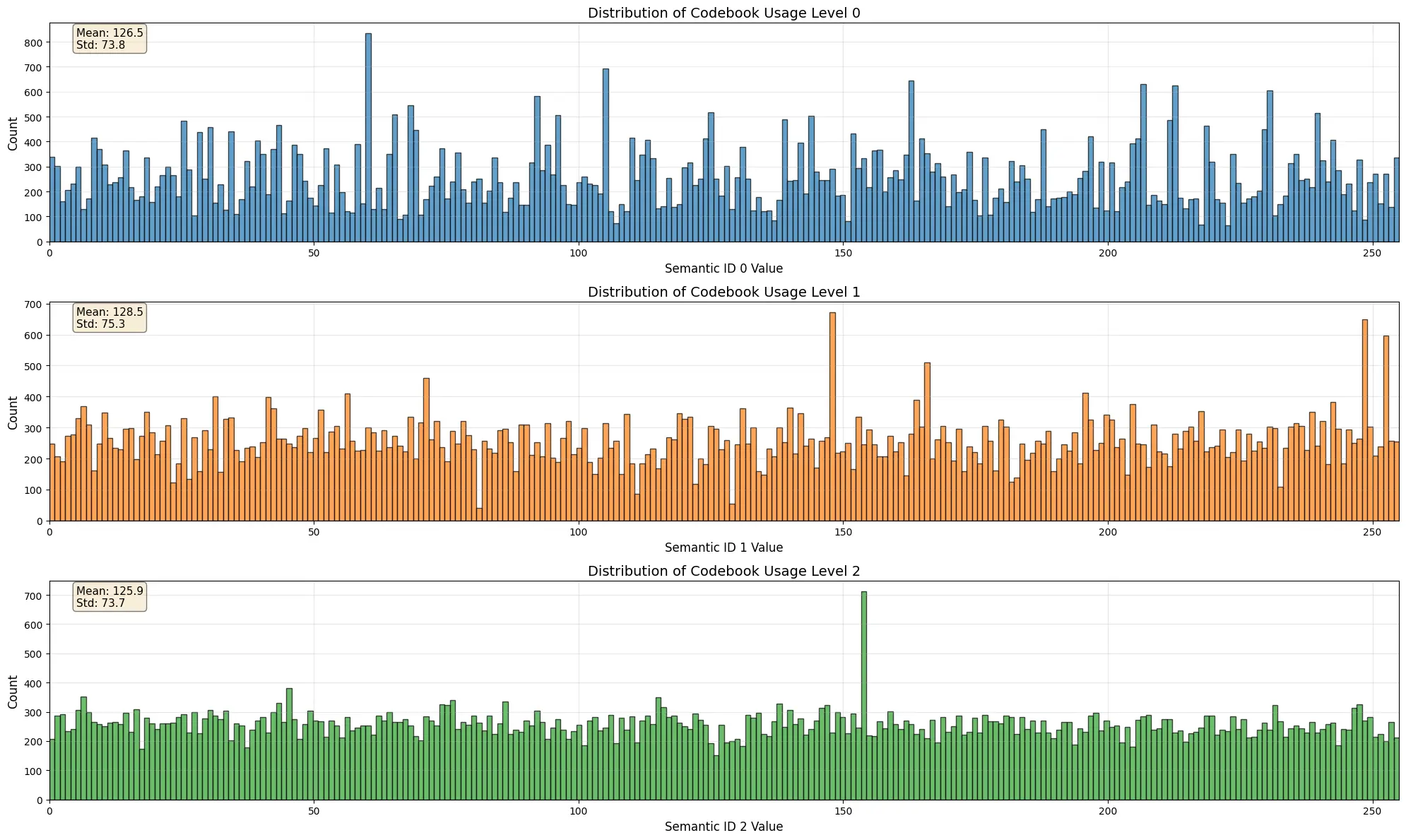
Пример RQVAE с хорошо распределённым использованием кодового словаря
Напротив, плохо сходящийся RQ-VAE будет иметь разреженное и сильно концентрированное использование кодов. Гистограмма ниже показывает этот режим отказа, где несколько кодов переиспользуются, а большинство кодового словаря игнорируется.
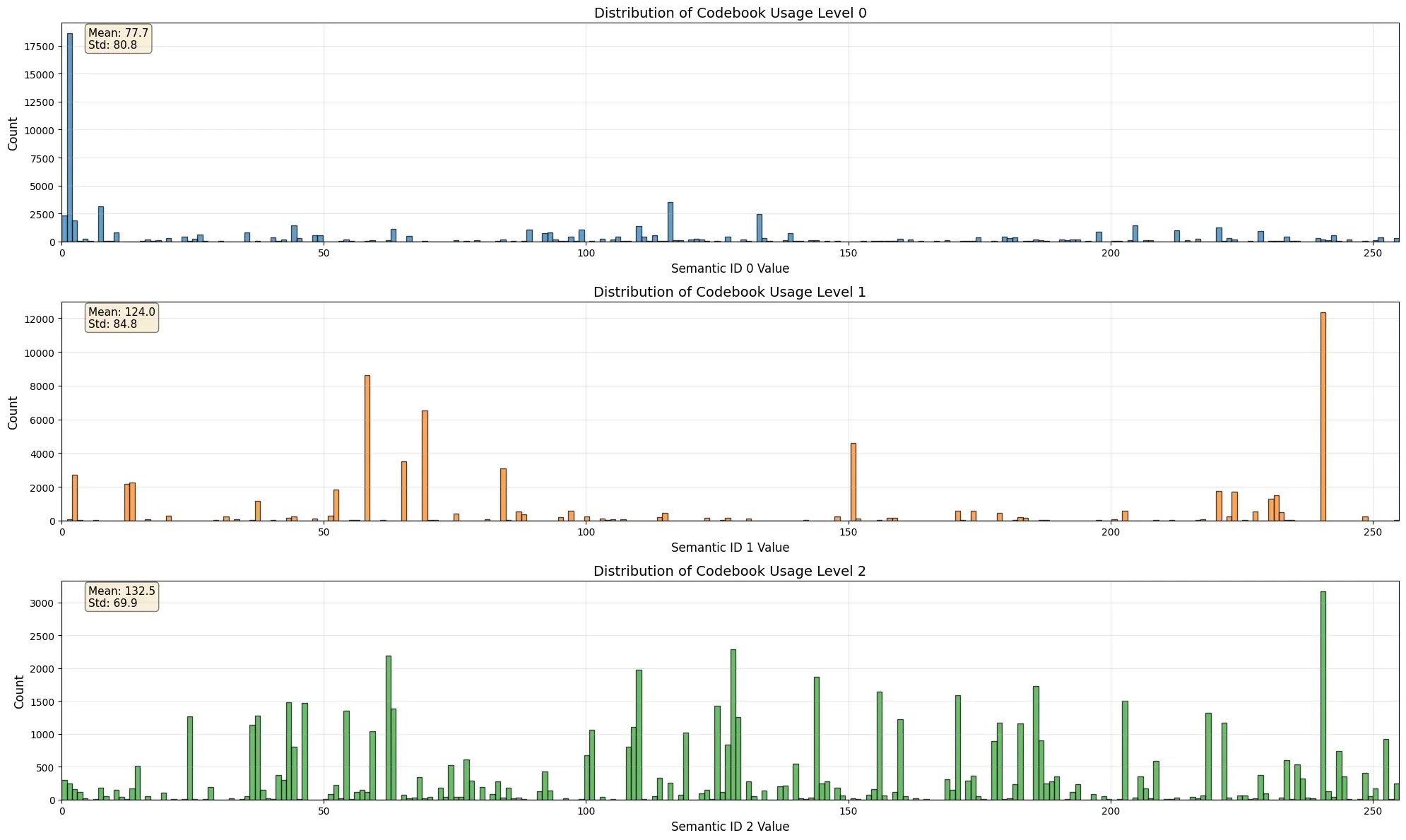
Пример RQVAE с плохо распределённым использованием кодового словаря
С обученным RQ-VAE мы кодируем все эмбеддинги товаров в формат их семантических ID, такой как <|sid_start|><|sid_191|><|sid_260|><|sid_716|><|sid_768|><|sid_end|>. Затем мы преобразовали 78.6k последовательностей покупок пользователей из обычных ID в последовательности семантических ID. Эти последовательности — обучающие данные, используемые как для валидации качества ID с базовой линией SASRec, так и для дообучения модели Qwen3-8B.
Обучение SASRec на обычных ID товаров vs. семантических ID
Чтобы валидировать, что наши семантические ID захватывают осмысленные отношения между продуктами, мы обучаем два варианта SASRec: базовую линию, обученную на обычных ID товаров, и вариант, обученный на семантических ID, затем сравниваем их производительность.
Базовая линия SASRec следует стандартной архитектуре. Она рассматривает каждый продукт как отдельную атомарную единицу, изучая эмбеддинг для него с нуля. Это основано чисто на поведенческих паттернах. Модель использует 2 каузальных блока self-attention, 64-мерное скрытое состояние и обучается на дискриминативной задаче различения следующего товара в последовательности от случайно выбранных отрицательных товаров, используя бинарную кросс-энтропию (BCE) потерю.
# Базовая линия SASRec функция предсказания
def predict(self, input_ids: torch.Tensor, candidate_ids: torch.Tensor) -> torch.Tensor:
"""Предсказать скоры для кандидатных товаров.
Args:
input_ids: Последовательности товаров [batch_size, seq_length]
candidate_ids: Кандидатные товары для скоринга [batch_size, num_candidates]
Returns:
Скоры для каждого кандидата [batch_size, num_candidates]
"""
# Получить представления последовательностей
hidden_states = self.forward(input_ids) # [B, T, H]
# Использовать только последнее скрытое состояние для предсказания
final_hidden = hidden_states[:, -1, :] # [B, H]
# Получить эмбеддинги кандидатов
candidate_embs = self.item_emb(candidate_ids) # [B, C, H]
# Вычислить скоры через скалярное произведение
scores = torch.bmm(candidate_embs, final_hidden.unsqueeze(-1)).squeeze(-1) # [B, C]
return scoresНапротив, SASRec на семантических ID переформулирует рекомендацию как условную генеративную задачу. Вместо скоринга товаров её цель — генерировать 4-частный семантический ID следующего товара, токен за токеном. Это требует более крупной архитектуры с 4 трансформерными блоками и 384-мерными скрытыми состояниями. В отличие от статьи TIGER, которая использует T5 encoder-decoder, этот вариант SASRec — decoder-only, что делает его более прямым и справедливым сравнением с базовой линией SASRec. Поскольку мы используем семантические ID, вместо эмбеддинга для каждого из 66k товаров у нас всего 1,024 токен-уровневых эмбеддинга, с 256 токенами на уровень в семантическом ID.
# SASRec на семантических ID функция предсказания
def predict_next_item(self, input_ids: torch.Tensor, teacher_forcing: bool = True,
target_tokens: Optional[torch.Tensor] = None) -> Dict[str, torch.Tensor]:
"""Предсказать токены семантического ID следующего товара последовательно.
Args:
input_ids: Токен-последовательности [batch_size, seq_length * num_levels]
teacher_forcing: Использовать ground truth для кондиционирования во время обучения
target_tokens: Ground truth токены для следующего товара [batch_size, num_levels]
Returns:
Словарь с логитами для каждого уровня
"""
hidden_states = self.forward(input_ids) # [B, T*L, H]
# Получить представление на последней позиции как контекст для всех предыдущих товаров
last_hidden = hidden_states[:, -1, :] # [B, H]
predictions = {}
# Последовательная генерация: предсказать каждый уровень, кондиционированный предыдущими
for level in range(self.num_levels):
if level == 0:
# Уровень 0: предсказать напрямую из представления последовательности
context = last_hidden
else:
# Уровни 1-3: кондиционировать на ранее предсказанных/истинных токенах
if teacher_forcing and target_tokens is not None:
# Использовать ground truth предыдущих уровней во время обучения
prev_tokens = target_tokens[:, :level] # [B, level]
else:
# Использовать предсказанные токены во время инференса
prev_tokens = self._sample_from_predictions(predictions, level)
prev_embeds = self.token_emb(prev_tokens) # [B, level, input_dim]
prev_embeds_projected = self.input_projection(prev_embeds) # [B, level, H]
prev_context = prev_embeds_projected.mean(dim=1) # [B, H]
# Объединить с контекстом последовательности
combined = torch.cat([last_hidden, prev_context], dim=-1) # [B, 2*H]
context = self.context_combiners[level - 1](combined) # [B, H]
# Предсказать текущий уровень
logits = self.level_heads[level](context) # [B, codebook_size]
predictions[f"logits_l{level}"] = logits
return predictionsЭтот генеративный подход меняет то, как мы обучаем и оцениваем. Функция потерь больше не простая BCE потеря, а сумма кросс-энтропийных потерь по каждому уровню семантического ID, заставляя модель предсказывать всю последовательность правильно. Оценка также более сложная, где вместо скалярного произведения скор товара — его совместная лог-вероятность, вычисляемая суммированием лог-вероятностей генерации каждого токена. Для улучшения стабильности обучения применяем teacher forcing, где ground-truth токен с предыдущего уровня помогает направлять предсказание для следующего уровня.
Для оценки обеих моделей используем валидационный набор, где мы добавили 500 отрицательных образцов для каждого положительного следующего товара. Хотя базовая линия SASRec превзошла вариант на семантических ID, производительность семантической модели уважительна, учитывая сложную генеративную задачу предсказания четырёх правильных токенов. Более того, вариант на семантических ID имеет способность обрабатывать cold-start товары, используя общие префиксы токенов от похожих продуктов, способность, которой не хватает базовой линии. Это раскрывает ключевой компромисс, где получение этой способности к обобщению требует в 4 раза больше предсказаний на товар и требует больше вычислений для обучения и инференса.
| Модель | Hit@10 | NDCG@10 | MRR | Mean Rank | Median Rank |
|---|---|---|---|---|---|
| Базовая линия SASRec | 0.2812 | 0.1535 | 0.1300 | 138.9 | 41.0 |
| SASRec на Semantic ID | 0.2020 | 0.1138 | 0.1007 | 179.7 | 79.0 |
Дообучение Qwen3-8B для рекомендации семантических ID
Далее мы учим языковую модель говорить на семантических ID. Для этого дообучаем Qwen3-8B, чтобы она стала “билингвальной”, свободно владеющей и естественным языком, и семантическими ID.
Сначала строим обучающий датасет из 4.2 миллиона разговорных примеров, чтобы научить модель семантическим ID и рекомендациям. Данные покрывают несколько типов задач, включая маппинг семантических ID к их соответствующим текстовым описаниям (и наоборот), предсказание следующего товара в последовательности пользователя, понимание отношений между категориями товаров и многошаговые рассуждения. Каждый из этих примеров отформатирован как разговоры с системным промптом, пользовательской инструкцией и ответом ассистента.
Затем дообучаем модель в две фазы. Первая фаза фокусируется на расширении словаря, где мы добавляем 1,027 новых токенов для семантических ID (т.е., <|sid_start|>, <|sid_end|>, <|sid_0|> до <|sid_1023|>, и <|rec|>) в токенизатор Qwen3-8B и изменяем размер матрицы эмбеддингов модели для них. Во время этой фазы мы замораживаем все параметры модели, кроме слоёв входного и выходного эмбеддингов, обучая 1.23B параметров (15.3% от общего количества) на 1,000 шагах с относительно высоким learning rate.
С инициализированными эмбеддингами токенов семантических ID переходим к следующей фазе полного дообучения на всех 8.3B параметрах. Для этого использовали более низкий learning rate, 3% расписание warmup и 8-bit AdamW оптимизатор для эффективности памяти, обучая три эпохи на полном датасете. Для мониторинга прогресса использовали несколько кастомных коллбэков, которые отслеживали метрики обучения вроде норм градиентов, измеряли иерархическую точность на задачах рекомендаций и сэмплировали выходы модели на фиксированном наборе разговорных входов.
Общение с гибридом LLM-рекоммендер
Дообученная модель может затем использоваться для рекомендации товаров и разговора на семантических ID и естественном языке. Поскольку семантические ID — нативная часть её словаря, модель генерирует рекомендации, просто предсказывая следующий ID в последовательности, токен за токеном. Для интерактивных сессий чат-интерфейс переводит сырой выход модели (который содержит семантические ID) обратно в названия продуктов, создавая человекочитаемый разговор.
Пользователь: “Halo 3 Limited Edition -Xbox 360”, “Lost Planet: Extreme Condition - Xbox 360”, “Lost Planet: Extreme Condition Collector’s Edition -Xbox 360”
<|rec|>Модель берёт историю взаимодействий пользователя (последовательность Xbox 360 sci-fi шутеров) и выполняет предсказание следующего товара.
<|sid_start|><|sid_64|><|sid_351|><|sid_733|><|sid_768|><|sid_end|>Ассистент: “Mass Effect - Xbox 360”
Базовые тесты показывают, что модель может предоставлять стандартные рекомендации следующего товара на основе истории пользователя и уточнять рекомендации на основе естественного языка, такого как ограничения платформы (“Xbox игры похожие на…”) или жанра (“Мне нравятся игры про животных и милые.”).
Пользователь: Xbox игры похожие на “The Legend of Zelda: Ocarina of Time 3D”:
<|rec|>Модель берёт seed товар (“The Legend of Zelda”) и ограничение на естественном языке (“Xbox”), чтобы направить рекомендации на другую платформу.
<|sid_start|><|sid_64|><|sid_271|><|sid_576|><|sid_768|><|sid_end|>, <|sid_start|><|sid_64|><|sid_435|><|sid_615|><|sid_768|><|sid_end|>, <|sid_start|><|sid_167|><|sid_271|><|sid_578|><|sid_768|><|sid_end|>Ассистент: “Fallout: New Vegas - Xbox 360 Ultimate Edition”, “Halo 4 - Xbox 360 (Standard Game)”, “Halo Reach - Legendary Edition”
Модель также может объяснять свои рекомендации, описывать отношения между двумя товарами и даже предлагать креативные названия и описания для наборов продуктов.
Пользователь: > Я только что закончил “Dragon Quest Heroes II Explorer’s Edition - PlayStation 4”. Предложи ещё один
<|rec|>и объясни почему:Модель выполняет гибридную задачу, где она генерирует релевантный семантический ID и затем предоставляет объяснение для рекомендации.
<|sid_start|><|sid_139|><|sid_289|><|sid_534|><|sid_768|><|sid_end|> Если вам понравился Dragon Quest Heroes II, вам может понравиться Nights of Azure потому что оба — action RPG для PlayStation 4 с фокусом на боевую систему и прогрессию персонажа. Обе игры предлагают нарративно- управляемый опыт с сильным акцентом на боевую механику, предполагая общий интерес игрока к этому жанру.Ассистент: “Nights of Azure - PlayStation 4”
Если вам понравился Dragon Quest Heroes II, вам может понравиться Nights of Azure потому что оба — action RPG для PlayStation 4 с фокусом на боевую систему и прогрессию персонажа. Обе игры предлагают нарративно-управляемый опыт с сильным акцентом на боевую механику, предполагая общий интерес игрока к этому жанру.
Наконец, хотя она может не соответствовать сырой точности специализированного рекоммендера, этот единый интерфейс позволяет пользователям открывать продукты из нашего каталога через многоходовый диалог, приводя к конвергенции поиска, рекоммендера и чата.
И всё это делается через саму модель, без классификаторов намерений, роутеров, retrieval и т.д.
[ХОД 1] Пользователь: Ищу игры похожие на Mario Kart.
<|rec|>Модель генерирует семантические ID для трёх карт-стиль гоночных игр.:
<|sid_start|><|sid_131|><|sid_503|><|sid_738|><|sid_768|><|sid_end|>, <|sid_start|><|sid_131|><|sid_260|><|sid_577|><|sid_768|><|sid_end|>, <|sid_start|><|sid_145|><|sid_416|><|sid_671|><|sid_768|><|sid_end|>Ассистент: “Need for Speed Most Wanted - Sony PSP”, “Need for Speed Hot Pursuit 2 - PlayStation 2”, “Burnout Legends - Nintendo DS”
[ХОД 2] Пользователь: А что-то похожее, но для Xbox?
Модель использует историю разговора и новое ограничение “Xbox” для генерации семантических ID для релевантных Xbox аркадных гонок.
<|sid_start|><|sid_183|><|sid_461|><|sid_517|><|sid_768|><|sid_end|>, <|sid_start|><|sid_183|><|sid_461|><|sid_562|><|sid_768|><|sid_end|>, <|sid_start|><|sid_183|><|sid_461|><|sid_616|><|sid_768|><|sid_end|>Ассистент: “Need for Speed Carbon - Xbox 360”, “Project Gotham Racing 3 - Xbox 360”, “Forza Motorsport 4 - Xbox 360”
[ХОД 3] Пользователь: Предложи название и описание для набора.
Модель понимает, что контекст сместился с рекомендации на креативную задачу генерации текста.
Ассистент: Xbox Racing Legends: Speed & Style Pack
Выводы
Обучение гибрида LLM и рекомендательной системы на семантических ID открывает новые возможности для управляемых рекомендаций с рассуждениями. Хотя модель может не достигать сырой точности специализированного многоэтапного рекоммендера, она предлагает уникальную способность к управляемости и объяснимости, создавая единый опыт для поиска, рекомендаций и чата.
Если бы у меня было больше вычислительных ресурсов, я бы экспериментировал с sentence piece токенизацией на семантических ID, которую Deepmind и Youtube нашли полезной, и дальше исследовал влияние семантических ID на cold-start. Также обучил бы RQ-VAEs и языковые модели на датасетах с миллионами товаров и большим разнообразием задач и разговоров, чтобы проверить, как этот подход масштабируется и обобщается.
Ссылки
- Hou, Yupeng, et al. “Bridging Language and Items for Retrieval and Recommendation”. arXiv:2403.03952, 2024.
- Amazon. “Amazon KDD Cup ‘23 - Multilingual Recommendation Challenge Dataset”. AIcrowd, 2023.
- Rajput, Shashank, et al. “Recommender Systems with Generative Retrieval”. arXiv:2305.05065, 2023.
- Singh, Anima, et al. “Better Generalization with Semantic IDs”. arXiv:2306.08121, 2024.
- Zeghidour, Neil, et al. “SoundStream: An End-to-End Neural Audio Codec”. arXiv:2107.03312, 2021.
- Lee, Doyup, et al. “Autoregressive Image Generation Using Residual Quantization”. arXiv:2203.01941, 2022.
- Kang, Wang-Cheng, and Julian McAuley. “Self-Attentive Sequential Recommendation”. arXiv:1808.09781, 2018.
- Vaswani, Ashish, et al. “Attention Is All You Need”. arXiv:1706.03762, 2017.
- Zhang, Yanzhao, et al. “Qwen3 Embedding: Advancing Text Embedding and Reranking”. arXiv:2506.05176, 2025.
- Yang, An, et al. “Qwen3 Technical Report”. arXiv:2505.09388, 2025.
- Comanici, Gheorghe, et al. “Gemini 2.5: Pushing the Frontier”. arXiv:2507.06261, 2025.
- Fifty, Chris, et al. “Efficient Training of Language Models with Gradient Quantization”. arXiv:2410.06424, 2025.