Голосовой AI для колл-центра
On-prem голосовой AI-оператор закрывает 72% звонков без человека за 0.96 с со снижением стоимости на 58%.

One-liner: 72% звонков без человека, ответ 0.96 с, −58% стоимости. On-prem и соответствует AI Act.
Ключевые метрики: Auto-resolve 72% • v2v p95 1.42 с • Cost per call −58% • Экономия в год: 420k $
Расчёт при N звонков/мес. и доле автоответов 72%. Формула - в “Экономика”.
Что делает система простыми словами
Проблема: 600 мест в контакт-центре банка, клиенты ждут 9 минут на линии, штрафы за SLA и новые требования AI Act. 64% вопросов повторяются (баланс карты, возвраты), но требуют живого оператора. Регламенты устаревают быстрее, чем успевают учить операторов.
Решение: голосовой AI оператор для колл-центра распознает речь в реальном времени, понимает интенты, ищет ответы в базе знаний и отвечает голосом за 0.96 секунды. Каскад моделей: быстрая 8B для типовых вопросов, мощная 70B для сложных. При необходимости передает оператору за ≤5 секунд.
Экономия: 72% звонков закрываются без человека, ожидание снизилось с 9 до 2.4 минут (минус 73%). Стоимость звонка упала с 3.90 $ до 1.64 $ (минус 58%). Годовая экономия 420k $, CSAT вырос на 1.9 пункта, жалобы в регулятор упали с 11 до 0 в квартал.
ML-часть: система использует Whisper v3 streaming для распознавания речи, Llama Guard для безопасности, Qdrant RAG для поиска в базе знаний и каскад Llama 3.1 (8B/70B) с TTS синтезом. Работает on-prem без передачи PII в облако, соответствует AI Act и GDPR, логи хранятся 180 дней.
Как пользоваться: 1) клиент звонит в колл-центр 2) AI распознает речь и находит ответ в базе знаний 3) отвечает голосом за 0.96 сек или передает оператору.
| Показатель | До | После | Как добились |
|---|---|---|---|
| Ожидание на линии (мин) | 9.0 | 2.4 | автоответы + приоритет очереди |
| Стоимость звонка ($) | 3.90 | 1.64 | каскад моделей + квантование |
| Жалобы в регулятор | 11/кв | 0 | логирование, объяснимость, oversight |
| Ночные смены | 46 | 18 | автоответы ночью + эскалации |
| Эскалации (% звонков) | 79 | 28 | автоответы + smart routing |
1. Контекст и вызовы
- 600 мест в контакт-центре банка: ожидание на линии 8.7-9.2 минуты и штрафы за нарушение SLA.
- 64% обращений повторяются (баланс карты, возвраты, перевыпуск), но требуют живого оператора.
- Регулятор (EU AI Act + GDPR) обязывает декларировать AI, хранить объяснимость и логи на 180 дней.
- Руководство хочет масштабируемый on-prem стек без передачи аудио и PII за пределы периметра.
Канареечный запуск: 2025-08-12. Окно метрик: 2025-08-19 → 2025-09-30 (warm-up неделя исключена).
2. Цели и KPI
| Метрика | Цель | Результат |
|---|---|---|
| Auto-resolve звонков | ≥ 65% | 72% |
| v2v p95 (95-й процентиль) | ≤ 1.5 с | 1.42 с |
| Стоимость звонка | −50% | −58% |
| CSAT (1-7) | +1.5 пункта | +1.9 |
| Жалобы регулятору | 0 | 0 |
| Handoff p95 | ≤ 5 с | ≤ 5 с |
Handoff p95: время от триггера risk-score/команды “оператор” до подключения ACD; p95 ≤ 5 с.
Методика: контрольная группа 30% трафика на human; доверительные интервалы 95%.
3. Как устроено (кратко)
5 шагов пайплайна:
- Вход - звонок через SIP/WebRTC
- Распознавание речи - стриминг в реальном времени
- Понимание + поиск - роутер интентов + база знаний
- Генерация ответа - каскад языковых моделей
- Ответ + эскалация - синтез речи или передача оператору
Идея: быстрый стриминг ASR → дешёвый путь (8B) для типовых → дорогой (70B) по необходимости → TTS/эскалация ≤ 5 с.
Результат: дешёвый путь закрывает типовые вопросы, дорогой включается только по необходимости, передача человеку - за ≤ 5 с.
Что мы сознательно НЕ делаем:
- Не отправляем PII в облако
- Не используем emotion recognition и биометрию - запрещено политикой
- Не отвечаем без цитат из базы знаний
- Осознанно держим on-prem
Подробности архитектуры и производительности - в разделе «Технические детали»
4. Impact (6 недель после запуска)
| Показатель | До внедрения | После запуска | Дельта |
|---|---|---|---|
| Ожидание на линии (мин) | 9.0 | 2.4 | −73% |
| Стоимость звонка ($) | 3.90 | 1.64 | −58% |
| CSAT (1-7) | 3.6 | 5.5 | +1.9 |
| Жалобы в регулятор | 11/квартал | 0 | −100% |
| Ночные смены | 46 | 18 | −61% |
| Auto-resolve (п.п.) | 21% | 72% | +51 |
5. Экономика
Cost per call снизили с 3.90 $ до 1.64 $ (−58%).
Чувствительность к изменениям:
- Сложные интенты +30% → 1.89 $ (+0.25 $)
- GPU outage (−1 сервер) → 1.97 $ (+0.33 $)
Источник - OTel-трейсы и биллинг GPU. Состав формулы
6. Комплаенс (чек-лист)
- Прозрачность - скрипт уведомляет об AI-операторе
- Хранение - логи 180 дней, аудио удаляется автоматически
- DSAR - запросы обрабатываются за 96 часов
- Контроль - человек всегда доступен по команде
- Объяснимость - каждый ответ ссылается на источник
- Безопасность - запрет эмоций и биометрии
- On-prem - PII остаётся on-prem; облачные сервисы не используются на клиентских данных
DSAR SLA: ≤ 96 ч; retention: 180 дней.
Документы и версии - в разделе «Технические детали»
7. Моя роль (ML / MLOps lead)
- Архитектура стриминга → v2v p95 −1.4 с
- Каскад моделей → −61% токенов
- RAG-контур → 0 жалоб регулятору за 6 недель
- Observability → MTTR инцидента 6 ч (case 2025-08-17)
- Compliance → DPIA v1.3, DSAR SLA ≤ 96 ч
8. Что дальше
- WhatsApp Voice - пилот до 2025-12-15, цель: 10% входящих, v2v p95 ≤ 1.5 с, handoff p95 ≤ 5 с
- AI-продажи - A/B 10% до 2025-11-30, цель: +7% CTR оффера, 0 жалоб
- Сертификация AI Act - пакет Q4/2025
- Помощник оператору - пилот Q1/2026
Технические детали
Скорость и масштаб
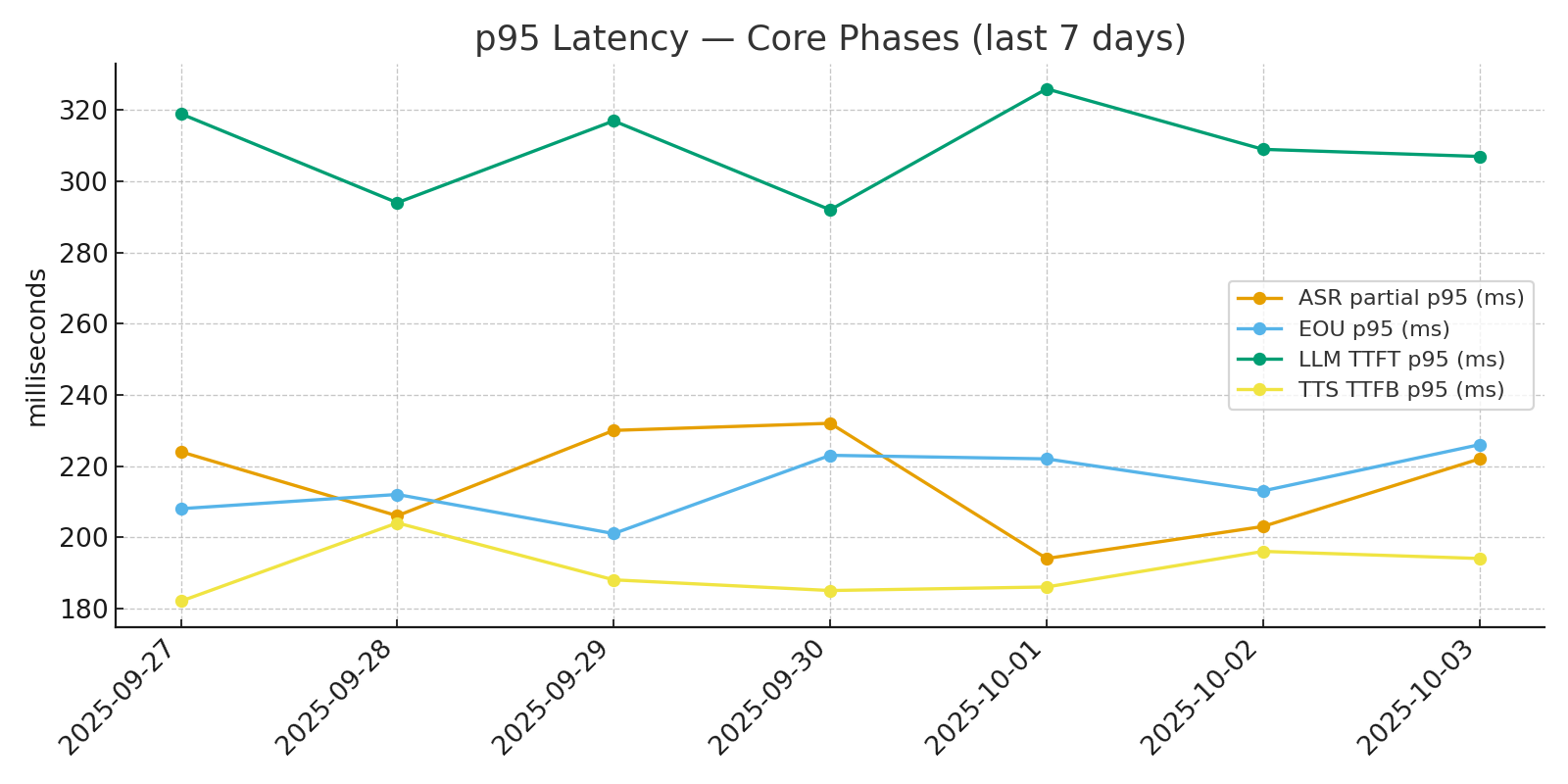
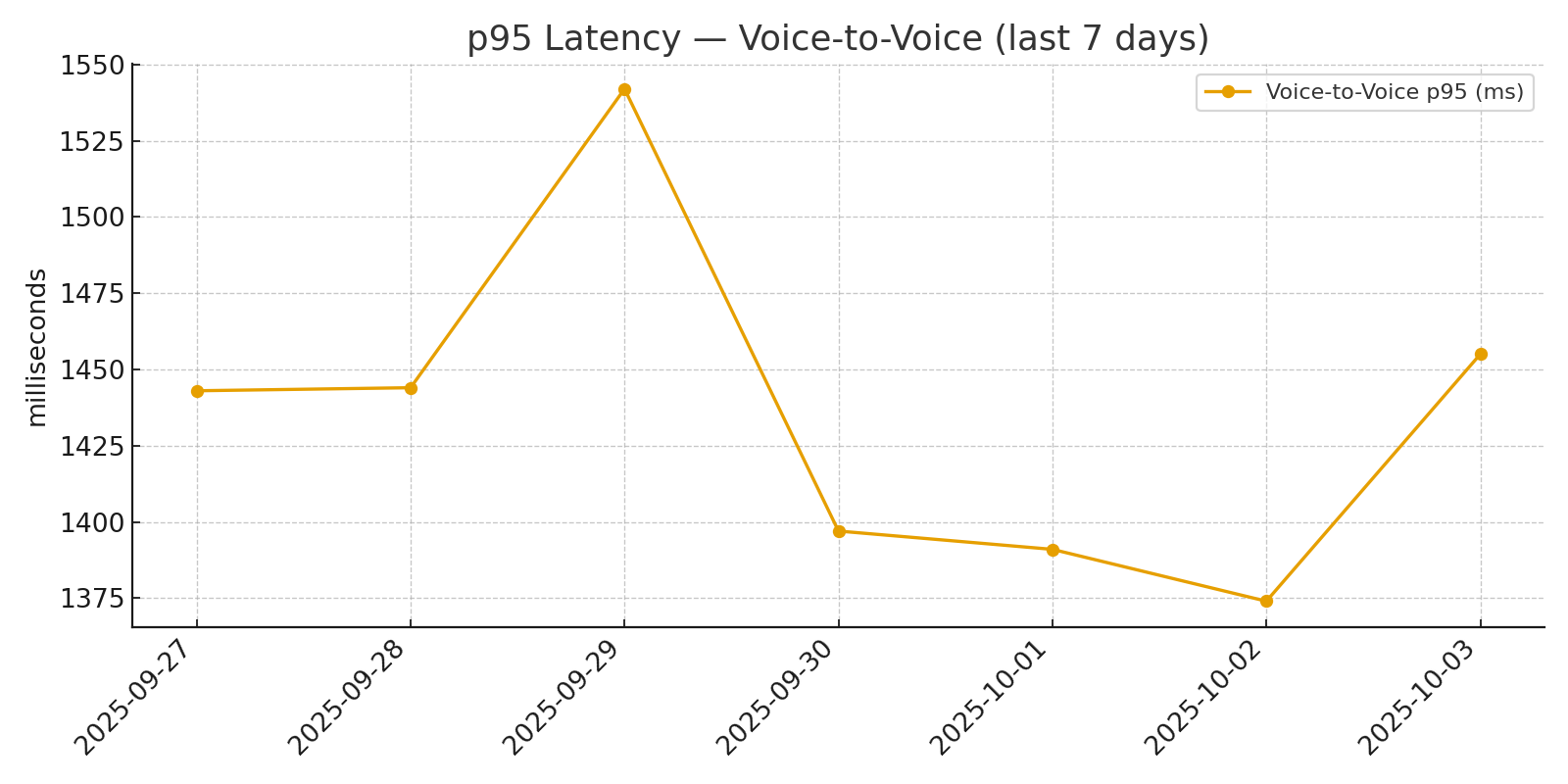
180 одновременных звонков • v2v p95 1.42 с • стриминг + каскад
Latency budget (4 ключевых стадии):
| Стадия | Цель (SLO) | Факт (среднее / p95) |
|---|---|---|
| ASR (распознавание речи) | ≤ 200 мс | 180 / 220 мс |
| EOU (конец фразы) | ≤ 250 мс | 160 / 212 мс |
| TTFT (первое слово AI) | ≤ 300 мс | 240 / 310 мс |
| v2v (от голоса до голоса) | ≤ 1500 мс | 960 / 1420 мс |
Capacity @ peak (4 компонента):
| Ресурс | Модель/сервис | Конкурентность | P95 latency |
|---|---|---|---|
| A100 80GB | Llama 3.1 70B | ≤3 сессий на пару GPU | 1.42 с |
| A100 80GB | Llama 3.1 8B | 6 сессий на MIG-слайс | 0.98 с |
| L40S | Whisper v3 | до 40 каналов | 0.22 RTF |
| L40S | TTS синтез | до 35 потоков | TTFB 168 мс |
Память и контекст
KV-cache для 8B/70B • eviction политики • оптимизация памяти
Формула: KV_bytes ≈ 2 · num_layers · kv_heads · head_dim · (context_tokens + new_tokens) · bytes_per_val
| Модель | Контекст | KV на сессию (fp16) |
|---|---|---|
| Llama 3.1 8B | 1.2k / 160 токенов | ~88 MB |
| Llama 3.1 70B NF4 | 1.2k / 160 токенов | ~215 MB |
Политики: LRU eviction при >12 сессиях (8B), sliding-window + eviction при >6 сессиях (70B)
Экономика
1.64 \$/звонок • разбивка по компонентам • ROI модель
Состав формулы (1.64 $/звонок):
| Компонент | Вклад |
|---|---|
| Energy | $0.02 |
| CapEx (GPU/CPU/сеть) | $0.46 |
| Software (MLOps) | $0.35 |
| Telco | $0.58 |
| Storage | $0.14 |
| Support | $0.09 |
Знания и RAG
База знаний • обновление за 3 мин • цитирование источников
- Источники: Google Drive, Jira, Confluence → webhooks + Dagster sync
- Обновление: chunk 160 слов → embeddings → upsert с version tag (SLA ≤ 3 мин)
- Поиск: вектор + фильтры, top-k=6 → re-ranker → ответ с цитированием
- Безопасность: allow-list источников, модерация документов, audit trail
Оркестрация и инструменты
Temporal workflows • авто-retry • SLO по инструментам
SLO по инструментам:
| Tool | Назначение | p90 SLA |
|---|---|---|
| check_limits | Остаток / лимиты карты | 200 мс |
| card_freeze | Блокировка карты | 250 мс |
| refund_status | Статус возврата | 220 мс |
| connect_human | Сигнал в ACD | 80 мс |
- Risk score:
risk = 0.5·toxicity + 0.3·low_confidence + 0.2·policy_violation(порог 0.4) - Fallback: ASR confidence < 0.75, > 3 повтора, нет документа → оператор
Наблюдаемость и качество
6 ключевых метрик • QA контур • алерты • adversarial eval
6 ключевых метрик: voice_to_voice_latency_ms, asr_partial_latency_ms, auto_resolve_rate, hallucination_flags_total, cost_cents_per_call, handoff_latency_ms
QA контур: 5% звонков прослушиваются, semi-auto scoring, WER по доменам
Алерты: TTFT p95 > 1.3×SLO 10 мин, dropout > 2%, hallucination > 3/час
Adversarial eval: nightly red-team 320 сценариев, pass-rate ≥ 98%
Справедливость и устойчивость
Fairness по акцентам • resilience tests • bias review
Fairness по акцентам (3 кластера):
| Кластер | WER (до) | WER (после) | Intent accuracy |
|---|---|---|---|
| RU центральный | 6.2% | 5.8% | 94.1% |
| RU южный/кавказский | 9.5% | 7.1% | 91.3% |
| EN с акцентом | 12.8% | 9.4% | 88.0% |
Остальные кластеры: скачать XLSX
Resilience: при 20% packet loss - v2v p95 1.55 с; при outage GPU - авто-fallback на 8B, SLA выдержан
SLO и бюджет ошибок
4 ключевых метрики • error budget • burn-rate алерты
- Voice-to-voice p95 ≤ 1.5 с (error budget 2%)
- Dropout rate ≤ 2% (бюджет 0.5%)
- Handoff SLA ≤ 5 с (бюджет 0.5%)
- Hallucination flags ≤ 1% диалогов
Burn-rate алерты: превышение 2× → стоп rollout
Безопасность и периметр
Zero Trust • mTLS • Vault • media/control/secrets
- Media plane: Kubernetes во внутреннем сегменте, аудио в Ceph (AES-256)
- Control plane: Temporal, Postgres, Qdrant - Zero Trust, mTLS, OIDC
- Secrets: HashiCorp Vault с HSM, ротация ключей каждые 90 дней
- Integrations: Genesys on-prem по mTLS, IP allowlist
Доказательная база по AI Act
Compliance пакет • версии • даты • документы
- Transparency script: v1.4 от 2025-08-01 - уведомление об AI-операторе
- DPIA/FRIA: документ v1.3.pdf (2025-07-22) - оценка рисков, утверждён CISO
- Retention & DSAR: TTL 180 дней, workflow удаления ≤ 96 ч
- Human oversight: эскалация по команде «оператор» и risk score > 0.4
- Explainability: каждый ответ хранит ссылку на документы + промпт; ExplainabilityPack-Q3.pdf (2025-09-30)
- Bias & safety: quarterly review, результаты в BiasReview-Q3.xlsx
Глоссарий
Термины • аббревиатуры • расшифровка
- ASR - Automatic Speech Recognition (автоматическое распознавание речи)
- DSAR - Data Subject Access Request (запрос на доступ к данным)
- EOU - End Of Utterance (конец фразы)
- p95 - 95-й процентиль (95% запросов быстрее этого значения)
- RAG - Retrieval Augmented Generation (генерация с поиском)
- SLA - Service Level Agreement (соглашение об уровне сервиса)
- TTFB - Time To First Byte (время до первого байта)
- TTFT - Time To First Token (время до первого токена)
- TTS - Text To Speech (синтез речи)
- v2v - voice-to-voice (от голоса клиента до голоса AI)
