Агент или workflow: как выбрать архитектуру без хайпа
TL;DR: В production-задачах вопрос обычно звучит не “нужен ли AI”, а “какой тип управления задачей нужен”. Если вход стабилен, критерии качества формализуются, а риск ошибки высок, базовым выбором остается workflow. Если задача меняется по ходу выполнения, требует выбора инструментов и адаптации плана, оправдан агент. На практике чаще работает гибрид: workflow как каркас, агент как ограниченный исполнитель в отдельных узлах.
Вокруг “агентов” накопилось много шума. Часть команд уходит в сложную оркестрацию слишком рано, часть, наоборот, держится за жесткий пайплайн там, где он уже ломает скорость разработки и качество результата. Обе крайности ведут к одинаковому эффекту: растет стоимость, деградируют сроки, а инженерные решения становятся менее прозрачными.
Ниже фиксируется практический фреймворк выбора. Он ориентирован на продакшн-контур: метрики, отказоустойчивость, безопасность, управляемая стоимость и понятная зона ответственности между кодом, моделью и человеком.
О чем именно идет речь
Чтобы избежать терминологического шума, полезно зафиксировать определения.
Workflow в этой статье это детерминированный граф шагов, где порядок переходов и условия ветвления описаны кодом. LLM встраивается как один из узлов, но система не делегирует ей право менять сам план выполнения.
Agent это исполнитель, которому делегируется выбор следующего шага в рамках заданных ограничений. Он может решать, какой инструмент вызвать, когда запросить дополнительный контекст и как пройти к цели через несколько итераций.
Гибридный вариант это workflow-каркас с ограниченными агентными узлами. Обычно такой вариант дает лучший баланс между надежностью и адаптивностью.
Почему выбор архитектуры важнее выбора модели
Команда может сменить модель за неделю. Архитектурный долг меняется дольше и дороже. Если базовый контур принят неверно, замена провайдера или промпта почти не влияет на итоговую экономику системы.
Ключевые риски ошибки выбора:
- переусложнение там, где достаточно детерминированного пайплайна;
- ложная надежность, когда workflow имитирует контроль, но не покрывает вариативность входа;
- размытая ответственность за ошибки между оркестратором, промптом и интеграциями;
- рост стоимости из-за лишних LLM-вызовов и повторных итераций.
В похожем production-контуре про релизы, безопасность и стоимость уже был разобран в отдельной статье про MLOps для RAG-агента. Текущий материал дополняет ее именно рамкой архитектурного выбора.
Признаки, что нужен workflow
Workflow обычно выигрывает, если одновременно выполняется большинство условий ниже.
- Вход хорошо структурирован или легко нормализуется.
- Критерии корректности формализуются в правила и тесты.
- Ошибка дорого стоит и требует предсказуемого поведения.
- Требуется понятный аудит каждого перехода.
- Нужна стабильная latency под SLO.
Типовые классы задач:
- extraction по шаблонам с валидацией схемы;
- классификация документов по фиксированной таксономии;
- подготовка отчетов с жестким форматом выхода;
- операционные runbook-процессы с allowlist действий.
Признаки, что оправдан агент
Агент оправдан, если задача действительно требует адаптивного планирования, а не просто “умного” текста в одном узле.
- Вход сильно вариативен и контекст собирается по ходу выполнения.
- Для достижения цели нужно выбирать между инструментами.
- Необходима многошаговая стратегия, где следующие шаги зависят от промежуточного результата.
- Важна скорость эволюции решения при меняющихся требованиях.
Типовые классы задач:
- исследовательские и аналитические контуры с разными источниками данных;
- triage сложных обращений, где нужно уточнение и ветвление сценария;
- полуавтоматические инженерные ассистенты, работающие с несколькими API.
Decision framework: 5 осей выбора
Ниже практическая рамка оценки. Каждая ось получает оценку от 1 до 5, где 1 это “ближе к workflow”, 5 это “ближе к агенту”.
| Ось | 1-2 (workflow) | 4-5 (agent) |
|---|---|---|
| Вариативность входа | Вход стабилен, схема понятна | Вход неоднородный, схема плавает |
| Детерминизм выхода | Строгий формат, жесткие правила | Допустимы альтернативные пути к цели |
| Инструментальная сложность | 1-2 инструмента, фиксированный порядок | Много инструментов, нужен динамический выбор |
| Цена ошибки | Ошибка критична, нужен полный контроль | Ошибка приемлема при эскалации человеку |
| Скорость изменений | Требования стабильны | Требования часто меняются |
Простое правило интерпретации:
- сумма
<= 12: базовый выбор workflow; - сумма
13-18: гибридный контур; - сумма
>= 19: агентный контур с жесткими guardrails.
Это не математическая истина, а рабочий инструмент согласования между инженерией, продуктом и бизнесом. Пороги лучше калибровать на истории собственных инцидентов, latency-ограничениях и фактическом cost_per_success.
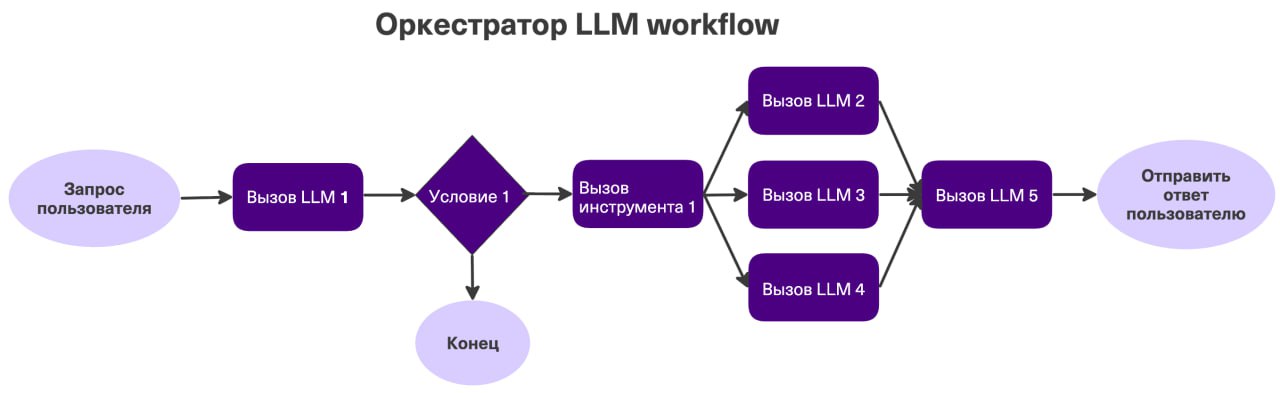
Три рабочих архитектурных паттерна
1) Детерминированный workflow с LLM-узлами
Input -> Validate -> Normalize -> LLM Task A -> Rule Check -> Output
| |
+--> Fallback Template -+Система остается управляемой. LLM отвечает только за ограниченный участок, а контур надежности обеспечивается кодом и правилами.
2) Гибрид: workflow-каркас + bounded agent
Input -> Policy Gate -> Agent Node -> Tool Proxy -> Validator -> Output
| |
+--> Escalate --+Это самый частый production-вариант. Агент получает свободу только внутри выделенного узла, а не над всей системой.
3) Мультиагентный граф
Goal -> Planner -> Specialist Agents -> Critic -> Aggregator -> OutputТакой вариант оправдан реже, чем принято думать. Его стоит выбирать только при доказанной пользе по метрикам и наличии зрелой observability-инфраструктуры.
Визуальный пример интерфейса с tool calling и агентным управлением можно посмотреть в посте про igorOS.
Контракт между оркестратором и инструментами
Большинство инцидентов в agent-системах происходят не из-за модели, а из-за слабых контрактов на границе tool calling. Базовый минимум: строгая схема входа/выхода, versioning, idempotency key, timeout budget и предсказуемые коды ошибок.
Пример минимального tool-контракта:
{
"tool_name": "create_ticket",
"version": "v1",
"input_schema": {
"type": "object",
"required": ["title", "severity", "service"],
"properties": {
"title": { "type": "string", "minLength": 8 },
"severity": { "type": "string", "enum": ["low", "medium", "high"] },
"service": { "type": "string" },
"idempotency_key": { "type": "string" }
}
},
"safety": {
"requires_human_approval": true,
"allowed_roles": ["sre", "l2_support"]
}
}Если такой контракт не существует, система еще не готова к масштабированию, независимо от качества промпта.
Evals: что мерить до релиза и после
В вопросе “agent vs workflow” победителя определяет не вкус команды, а измеряемый результат.
Минимальный набор offline-evals:
task_success_rateпо целевым сценариям;tool_call_precisionиtool_call_recall;- доля ошибок маршрутизации;
- доля нарушений policy;
- стоимость решения задачи (
cost_per_success).
Минимальный набор online-метрик:
p95 latencyиtimeout rate;human_escalation_rate;rollback rateпо релизам;incident_countпо критичности;user_acceptance_rateдля бизнес-функции.
SLO удобнее фиксировать до дискуссии о “качестве модели”. Это дисциплинирует архитектурные решения и убирает эмоциональные споры.
Для примера, где качество системы разбирается на конкретных метриках и этапах дообучения, полезен разбор Semantic IDs + LLM в рекомендательной системе.
Observability для agent-контуров
Без трассировки шагов агент быстро превращается в “черный ящик”. Нужен единый trace на весь жизненный цикл задачи: от входного запроса до фактического действия инструмента.
Полезный минимальный лог-событий:
request_id
session_id
planner_decision
selected_tool
tool_input_hash
tool_result_status
policy_check_status
human_approval_status
total_tokens
total_cost_usd
latency_msЭтого достаточно, чтобы разбирать инциденты и строить release-gates на данных, а не на ощущениях.
Безопасность: где обычно ломается агент
При переходе от workflow к агенту поверхность атаки расширяется: появляется динамический выбор инструментов и больше точек, где внешняя строка может повлиять на поведение системы.
Базовые guardrails:
- строгий allowlist инструментов, запрет неописанных вызовов;
- изоляция секретов, отсутствие прямого доступа модели к credential store;
- policy-check перед каждым side-effect действием;
- обязательное human approval для необратимых операций;
- фильтрация и маркировка недоверенного контента в контексте.
Это полностью согласуется с практиками OWASP Top 10 for LLM Applications и NIST AI RMF: Generative AI Profile.
Стоимость: как принять решение без самообмана
Сравнение workflow и агента стоит делать не по “цене запроса”, а по “цене успешно завершенной задачи” в целевой бизнес-функции.
Рабочая формула:
Cost per useful task =
(LLM_cost + Tool_cost + Infra_cost + Human_review_cost) / Success_countЕсли агент снижает ручной труд, но резко увеличивает эскалации и повторные итерации, итоговая экономика может оказаться хуже workflow. Поэтому cost-модель всегда рассматривается вместе с качеством и временем.
Практический план внедрения: от workflow к агенту
Этап 0. Базовый workflow
Сначала фиксируется детерминированный процесс. На этом этапе собирается эталон качества и стоимости.
Этап 1. Один агентный узел
Агент добавляется в один участок с высокой вариативностью входа. Остальная система остается в workflow-каркасе.
Этап 2. Release-gates и policy
Вводятся обязательные гейты перед выкладкой: eval-порог, budget-порог, policy compliance. Любой промоут релиза блокируется при нарушении порогов.
Этап 3. Масштабирование по бизнес-функциям
После стабильной работы в одном контуре агентный подход переносится на соседние функции. Каждая новая функция получает свой eval-набор и собственный SLO-профиль.
Такой порядок обычно снижает риск “большого архитектурного разворота”, когда система усложняется быстрее, чем команда успевает ее наблюдать и поддерживать.
Анти-паттерны, которые встречаются чаще всего
- Агент без границ ответственности. Не определено, где заканчивается автономия и начинается ручной контроль.
- Ставка на промпт вместо контракта. Вход и выход инструментов не формализованы.
- Оценка по демо, а не по прод-метрикам. В пилоте все выглядит лучше, чем под нагрузкой.
- Отсутствие budget controls. Стоимость отслеживается постфактум.
- Смешение ролей модели и оркестратора. Модель начинает решать вопросы, которые должен решать код.
Open-source опора для статьи
Для систематизации архитектурных решений удобно использовать репозиторий:
Этот материал полезен как инженерный чеклист: как проектировать tool calls, контекст, состояние и границы ответственности в агентных системах. В рамках текущей темы его удобно применять как “дизайн-ревью шаблон” перед релизом.
В качестве прикладного примера интеграций через API можно дополнительно посмотреть:
Этот репозиторий показывает практическую связку между OpenAPI и MCP-сервером и хорошо ложится в сценарий “workflow-каркас + ограниченный агент”.
Короткий итог
В production выбор между agent и workflow это не идеологический спор. Это инженерная задача с измеряемыми входами: вариативность, риск, стоимость и требуемая скорость изменений.
Стартовая позиция почти всегда workflow. Агентный подход добавляется точечно, когда данные показывают, что адаптивность действительно дает прирост по целевой бизнес-метрике.
Когда архитектурный выбор фиксируется через контракт, evals и policy, система остается управляемой даже при росте сложности.