Offline-online разрыв в RecSys: 11 релизных гейтов и регламент инцидентов
TL;DR: Рост офлайн метрик в deep learning RecSys часто означает, что модель точнее воспроизвела свойства исторических логов, а не то, что система улучшит продукт в живом трафике. Причина не одна: feedback loops, selection/exposure/position bias, delayed labels, train/serve skew, смещение negative sampling, рассинхрон целей между стадиями и экономикой. Рабочий ответ состоит из инженерного контура: корректное логирование, контрфактическая оценка с явными ограничениями, point-in-time корректность фичей, многостадийные релизные гейты, shadow/canary/rollback и регламент инцидентов.
Как читать этот материал
- Если нужно быстро принять решение по релизу: перейти к разделам 8, 9, 10, 11, 13.
- Если нужно найти корень деградации
офлайн плюс / онлайн минус: пройти разделы 1, 2, 3, 4, 5, 6, 7, затем раздел 11. - Если задача построить стабильный процесс на квартал: взять разделы 8, 9, 12, 13, 14, 15 как основу плана работ.
Зачем этот материал
Материал собран как рабочая шпаргалка для команды, которая уже запускала или запускает DL-рекомендательную систему и сталкивалась с конфликтом:
- офлайн отчет показывает улучшение;
- после релиза продуктовые KPI ухудшаются или становятся нестабильными;
- деградация становится заметной только через дни или недели.
Цель: разобрать корневые механизмы, зафиксировать границы применимости методов и дать операционный шаблон, который снижает риск регресса на релизе.
Что именно считается offline-online разрывом
В терминах инженерной эксплуатации разрыв фиксируется так:
где:
Offline: метрики на исторических логах или в offline replay;Online: KPI в живом трафике, включая ограничения по качеству, надежности и экономике.
Ключевая мысль: после выкладки policy меняется экспозиция. Это значит, что распределение наблюдений перестает быть тем же, на котором считался офлайн отчет. Этот структурный сдвиг подтверждается в обзорах и simulation-работах по feedback loops 2025-2026 годов: Systematic review, Simulation framework, Diversity paradox revisited, JIIS 2026.
Карта причин: что чаще всего ломает прод
| Причина | Что ломается | Как выглядит в метриках | Что проверить сначала |
|---|---|---|---|
| Петли обратной связи (feedback loops) | Модель меняет будущие логи и усиливает свои перекосы | краткосрочные метрики растут, долгосрочные уходят вниз | cohort-анализ до/после релиза + ретрейн-итерации |
| Смещение выборки и экспозиции (selection/exposure bias) | Логи не репрезентативны для новой policy | офлайн переоценивает кандидатов из исторической экспозиции | есть ли propensity, position и exposure в логах |
| Отложенные метки (delayed labels) | В свежем окне много незрелых меток | ранний плюс, поздний минус | доля незрелых исходов по целевым KPI |
| Расхождение train/serve (training-serving skew) | Расходятся train и serve признаки | скачок score distribution после релиза | parity train/serve на serving snapshot |
| Смещение негативного сэмплирования (negative sampling bias) | Retrieval искажается из-за схемы негативов | recall/coverage падают на живом трафике | аудит sampling policy и logQ-коррекции |
| Несоответствие цели (objective mismatch) | Оптимизируется не та целевая ценность | CTR растет, удержание/удовлетворенность деградируют | есть ли жесткие ограничения на прикладные KPI |
| Сцепка стадий (stage coupling) | Локальный выигрыш ломает end-to-end | retrieval лучше, общий feed хуже | stage-level attribution и funnel диагностика |
| Нестационарность и дрейф (non-stationarity/drift) | Контекст быстро меняется | деградация без явного инцидента | drift + freshness + slice мониторинг |
1) Feedback loops: офлайн иллюзия при многократном retraining
Система рекомендаций формирует поведение пользователей, поведение становится новыми данными обучения, затем модель переобучается на собственных следах. Это замкнутый контур. В статичном offline split такой контур не моделируется полностью, поэтому часть улучшений оказывается иллюзией.
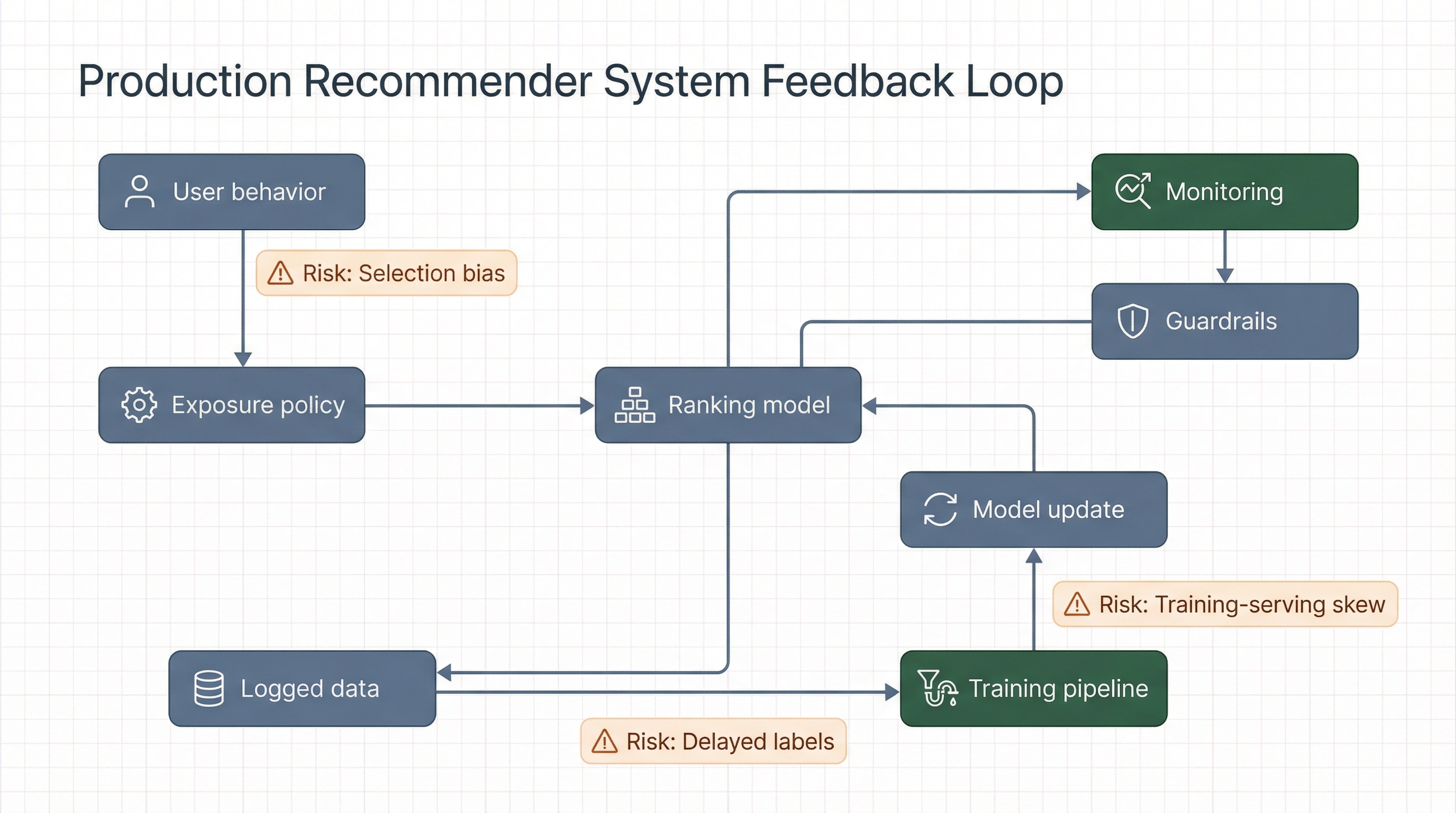
Схема feedback loop: почему офлайн прирост на исторических логах не гарантирует улучшение после смены policy в живом трафике.
Что важно из свежих работ:
- в 2025-2026 подчеркивается дефицит multi-round валидации, при том что именно она критична для оценки долговременного эффекта: SLR 2025;
- симуляции с периодическим retraining показывают системные эффекты на разнообразие и концентрацию: 2510.14857, 2602.16315;
- журнальные публикации в 2026 поддерживают вывод о риске усиления popularity bias и group disparity: JIIS 2026.
Практический вывод для прода:
- Однократную offline-оценку не использовать как финальный аргумент для 100% rollout.
- До полного релиза обязателен контур shadow/canary с отслеживанием cohort fairness и разнообразия.
- Для критичных поверхностей вводить многошаговую replay- и simulation-оценку.
2) Смещения selection/exposure/position: почему исторические логи обманывают
Исторические логи в RecSys это данные, сгенерированные прежней policy и интерфейсом показа. Пользователь не может взаимодействовать с объектами, которые не были показаны. Это классический MNAR-контекст.
Базовые фундаментальные работы:
- контрфактическое обучение и оценка для рекомендаций: Recommendations as Treatments, ICML 2016;
- unbiased learning-to-rank под bias в feedback: Joachims et al..
Актуальные подтверждения в 2025:
- в практических публикациях RecSys 2025 системно встречаются темы exposure bias, debiasing и надежности sampling/OPE: Accepted contributions 2025;
- вопрос offline-online alignment продолжает быть отдельной исследовательской задачей: RecSys 2025 poster index.
Базовая формула IPS:
где μ это logging policy, π это target policy.
Важно: это форма IPS для single-action contextual bandit. Для ranking/slate-оценки нужны position-aware или slate-aware propensity-модели.
OPE также предполагает positivity/overlap и достаточно точную оценку propensity. В реальных RecSys-логах оба предположения часто нарушаются.
Критическое ограничение: при unobserved confounding даже аккуратная OPE-оценка может оставаться смещенной. Поэтому OPE нельзя использовать как единственный пропуск в прод. Это ограничение подробно разобрано в Jeunen & London, 2023.
3) Delayed labels: ложные негативы и сдвиг оценки
В рекомендательных системах в проде целевой сигнал часто отложен:
- конверсия приходит позже клика;
- долгий просмотр или возврат в сервис фиксируется через окно;
- часть событий созревает с большой задержкой.
Если обучение идет на слишком свежем окне, возникает системный перекос: положительный исход еще не проявился, событие ошибочно попадает в негатив.
Актуальные источники:
- Delayed Feedback Modeling with Influence Functions (2025);
- Neural Contextual Bandits Under Delayed Feedback Constraints (2025).
Практический контур:
- Два горизонта метрик: оперативный и зрелый.
- Отдельная метрика зрелости меток в релизном дашборде.
- Решение о полном rollout не принимать по незрелому окну.
- Для delayed KPI вводить non-inferiority guardrail на зрелых данных.
4) Расхождение train/serve: самая дорогая ошибка без шума
Расхождение возникает, когда train и serve фактически видят разные признаки: отличия в трансформациях, джойнах, тайминге, схемах, коде препроцессинга, кэше.
Официальные практики:
- Rules of ML (Google, updated 2025-08-25);
- Feast joins PyTorch ecosystem (2026);
- Databricks point-in-time joins;
- Feast documentation.
Практический минимум:
- единый код трансформации для train и serve;
- обязательный
feature_snapshot_idв serving логе; - point-in-time join для обучения без time leakage;
- parity-тест перед canary.
Для короткого, но прикладного шаблона релизного контракта можно использовать материал MLOps для production ML: 7 релизных гейтов, а этот документ оставить как расширенную версию с акцентом на offline-online разрыв.
5) Negative sampling bias: скрытый источник retrieval-регресса
В deep retrieval-сценариях качество сильно зависит от того, как формируются негативы. Если негативы слишком легкие, смещенные по частоте или не соответствуют продовой экспозиции, offline loss улучшается, а онлайн качество падает.
Современные источники:
- Negative Sampling in Recommendation: A Survey and Future Directions (подана 2024-09-11, ревизия 2025-07-25);
- Correcting the LogQ Correction: Revisiting Sampled Softmax for Large-Scale Retrieval (2025);
- On the Effectiveness of Sampled Softmax Loss for Item Recommendation, TOIS 2024;
- open-access preprint для sampled-softmax анализа: SSM: A Revisitation of Scaled Softmax for Recommender Systems;
- динамика тематических треков RecSys 2025 в части exposure/sampling: accepted contributions.
Что проверять в релизе:
- Частотное распределение негативов по head/mid/tail.
- Долю hard negatives по сегментам.
- Локальную устойчивость recall@K по slice.
- Покрытие (coverage) и новизну (novelty) на живом трафике.
- Согласованность sampling policy между offline training и online funnel.
6) Несоответствие цели и сцепка стадий
В системе в проде есть цепочка стадий: retrieval, ранний ranking, поздний ranking, reranking. Локальное улучшение на одной стадии не гарантирует улучшение end-to-end KPI.
Инженерные разборы крупных систем:
- Instagram recommendation system scaling (Meta, 2025);
- Instagram Explore architecture (Meta, 2023);
- YouTube Deep Neural Networks for Recommendations (RecSys 2016).
Ключевой инженерный тезис: при оптимизации только CTR система может уходить в нежелательные режимы (clickbait-поведение, падение удержания). Поэтому нужна многоцелевая постановка с жесткими ограничениями.
Практический пример многостадийной логики retrieval/ranking с бизнес-ограничениями разобран в статье Обучение гибрида LLM и рекомендательной системы на Semantic IDs.
Пример рабочей ценности:
Важно: формула без hard constraints это не продовый контур. Ограничения задаются отдельно как блокирующие условия релиза.
7) Минимальный лог-контракт для корректной диагностики
Без хорошего лог-контракта offline-online разрыв не диагностируется корректно.
| Поле | Назначение |
|---|---|
request_id | end-to-end трассировка |
session_id, user_id | cohort и последовательность поведения |
event_ts | event-time семантика |
policy_id, model_version | воспроизводимость выкладки |
rank_position, surface | учет presentation bias |
candidate_source, stage | диагностика stage coupling |
propensity | OPE и дебайсинг |
feature_snapshot_id | parity train/serve |
item_id, score_vector | анализ решений модели |
reward, delayed_reward_ts | разделение immediate и delayed сигналов |
latency_ms, timeout, error_code | надежность и SLO |
cost_tokens, infra_cost | экономика полезного исхода |
Пример записи:
request_id: 32b9c11d
session_id: s_8841
user_id: u_20144
event_ts: 2026-02-26T13:20:11Z
policy_id: feed_rank_v188
model_version: ranker_2026_02_26_7
surface: home_feed
stage: ranker_late
rank_position: 6
candidate_source: two_tower_retrieval
item_id: i_991244
propensity: 0.0241
feature_snapshot_id: fs_online_2026_02_26_1320
scores:
p_click: 0.162
p_long_watch: 0.071
p_return_7d: 0.053
labels:
click: 1
long_watch_30s: null
return_7d: null
runtime:
latency_ms: 94
timeout: false
economics:
infra_cost_usd: 0.000418) Релизный протокол: 11 гейтов перед 100% трафика
Ниже расширенный протокол для deep learning RecSys. Он опирается на практики безопасной выкладки в прод и масштабирование многомодельных рекомендаций: Uber deployment safety, Meta production engineering 2025.
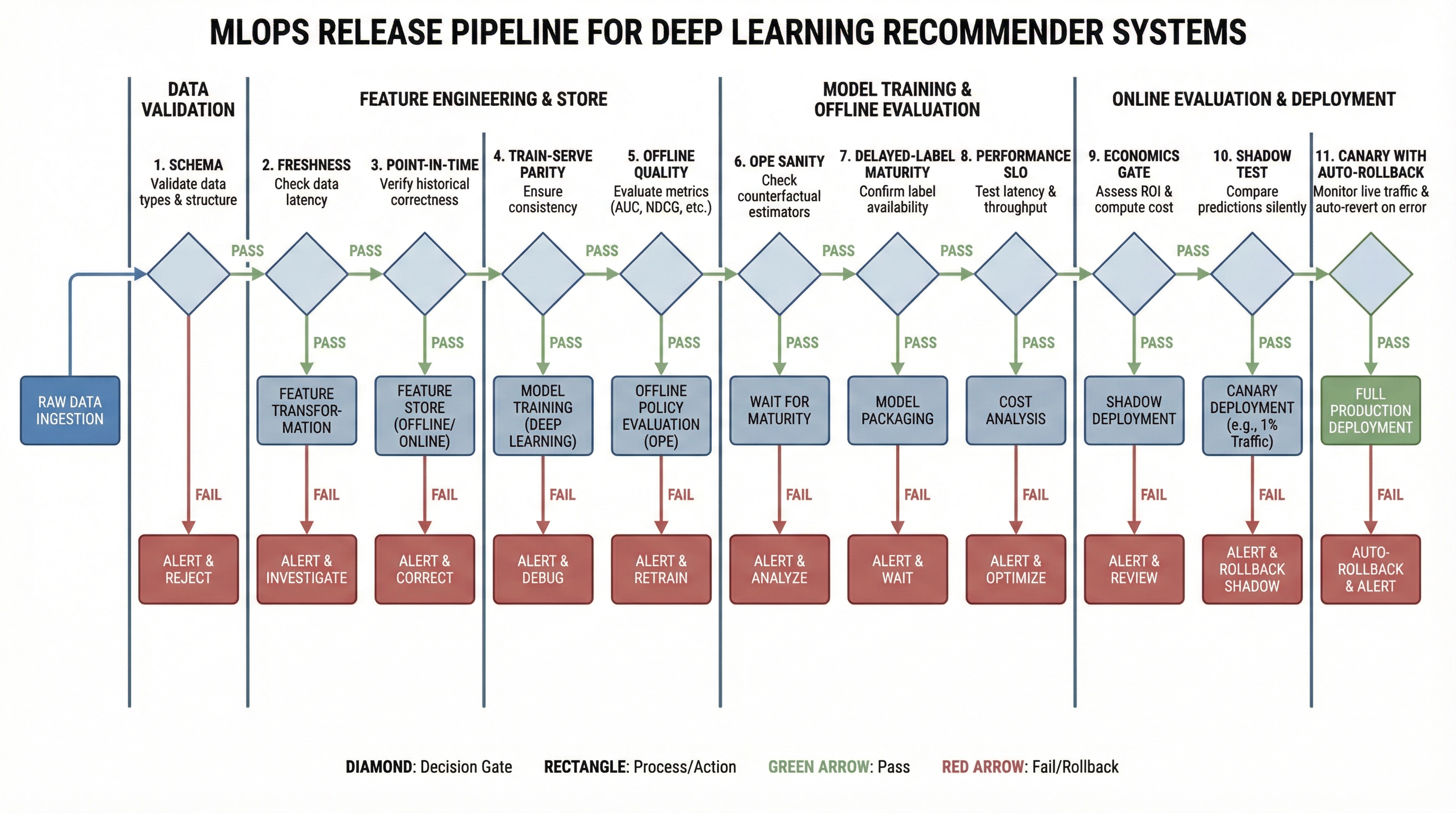
Расширенный релизный конвейер: каждый гейт блокирует релиз при риске деградации качества, SLO или экономики.
- Схемный гейт (Schema gate): входная схема и типы согласованы.
- Гейт свежести (Freshness gate): данные в SLA по свежести.
- PIT-гейт (PIT gate): point-in-time join без leakage.
- Гейт паритета (Parity gate): train/serve feature parity в допуске.
- Гейт качества офлайн (Offline quality gate): основные и slice метрики в допуске.
- Проверка OPE (OPE sanity gate): OPE не противоречит базовым онлайн ожиданиям и имеет ограниченную дисперсию.
- Гейт отложенных меток (Delayed-label gate): зрелость ключевых меток достаточна для решения.
- Гейт производительности (Performance gate): p95/p99 latency и timeout rate в SLO.
- Стоимостной гейт (Economics gate): cost per useful outcome не деградирует выше порога.
- Shadow-гейт (Shadow gate): расхождения на shadow-трафике в пределах допусков.
- Гейт canary/rollback (Canary/rollback gate): автооткат проверен на учении, стоп-условия формализованы.
9) Набор метрик: без чего решение о релизе некорректно
9.1 Data
- null-rate и schema violations;
- freshness lag;
- drift/skew по ключевым признакам;
- доля событий с полноценным лог-контрактом.
9.2 Model
- score distribution;
- calibration error;
- entropy по сегментам;
- recall@K / nDCG@K на контрольных cohort.
9.3 Product
- CTR как вспомогательная метрика;
- прикладные KPI: long watch, retention proxy, complaint rate;
- coverage, novelty, diversity по cohort.
9.4 Economics
- infra cost;
- cost per useful outcome;
- доля ресурсов на retraining и online inference;
- разница между прогнозной и фактической экономикой после rollout.
9.5 Быстрая диагностика: симптом -> вероятная причина -> первое действие
| Симптом после релиза | Наиболее вероятная причина | Первое действие |
|---|---|---|
| CTR вверх, retention вниз | Несоответствие цели | Проверить guardrails по долгосрочным KPI и ограничить rollout |
| Offline nDCG вверх, online recall вниз | Negative sampling bias | Пересчитать retrieval с аудитом sampling policy и slice-метриками |
| Резкая деградация сразу после выкладки | Train-serve skew | Запустить parity-проверку на live snapshot и сравнить feature pipeline |
| Ранние метрики хорошие, через 3-7 дней просадка | Delayed labels | Пересчитать решение на mature окне, заморозить масштабирование rollout |
| Рост head-контента и падение разнообразия | Feedback loop + exposure bias | Включить cohort/diversity ограничения и снизить агрессивность policy |
9.6 Референсные пороги для релизных гейтов (стартовые значения)
Ниже не универсальные истины, а рабочая отправная точка для первой рабочей версии. Пороги нужно калибровать по своей базе и сезонности.
| Контур | Метрика | Зеленая зона | Желтая зона | Красная зона |
|---|---|---|---|---|
| Надежность | p95 latency | <= +5% к базовой версии | +5% .. +10% | > +10% |
| Надежность | timeout rate | <= 0.5% | 0.5% .. 0.8% | > 0.8% |
| Качество | long-term KPI (retention proxy) | >= 0 дельта | 0 .. -1.5% | < -1.5% |
| Качество | coverage@K | >= -1% | -1% .. -3% | < -3% |
| Качество | diversity/novelty | в допуске по guardrail | незначимое снижение | значимое снижение |
| Данные | parity train/serve | в допуске | частичные расхождения | системный skew |
| Экономика | cost_per_useful_outcome | <= +3% | +3% .. +8% | > +8% |
Правило эскалации:
- Любая красная зона блокирует расширение canary.
- Желтая зона допустима только при явном плане коррекции и ограниченном трафике.
- В 100% трафика можно идти только при отсутствии красной зоны и контролируемой желтой зоны.
10) Экспериментальный протокол: как связать offline и online
Шаблон минимального цикла:
- Сформировать shortlist моделей по offline + slice + stability.
- Для каждой модели зафиксировать гипотезу влияния на прикладные KPI.
- Прогнать shadow с тем же лог-контрактом, что в проде.
- Запустить canary
5% -> 25% -> 50% -> 100%с автостопом. - Отдельно оценить immediate KPI и delayed KPI.
- Зафиксировать, какие offline признаки действительно предсказывают онлайн исход.
Если в системе есть оркестратор и сложные ветки принятия решений, отдельно стоит сверить архитектурный выбор с критериями из статьи Агент или workflow: как выбрать архитектуру без хайпа.
Базовые stop-conditions:
canary_stop_conditions:
- p95_latency_ms > 180 for 10m
- timeout_rate > 0.8% for 5m
- retention_proxy_delta < -1.5% after maturation_window
- cost_per_useful_outcome_delta > +8%10.1 Как проверить, что offline-метрика реально предсказывает online
Частая ошибка: считать любую offline-метрику “доказательством” будущего прироста. Нужна отдельная проверка предиктивности.
Минимальный протокол:
- Собрать
N >= 8релизов с одинаковым измерительным контуром. - Для каждого релиза зафиксировать
delta_offlineиdelta_onlineна зрелом окне. - Посчитать ранговую связь (Spearman), а не только линейную корреляцию.
- Посчитать связь с лагами
0/7/14дней для delayed KPI. - Оставить в отчете по релизу только те offline-метрики, у которых связь стабильна по окнам.
Если метрика нестабильна по знаку связи, она не должна быть релизным гейтом, только вспомогательным индикатором.
11) Регламент инцидента: когда офлайн плюс, а онлайн минус
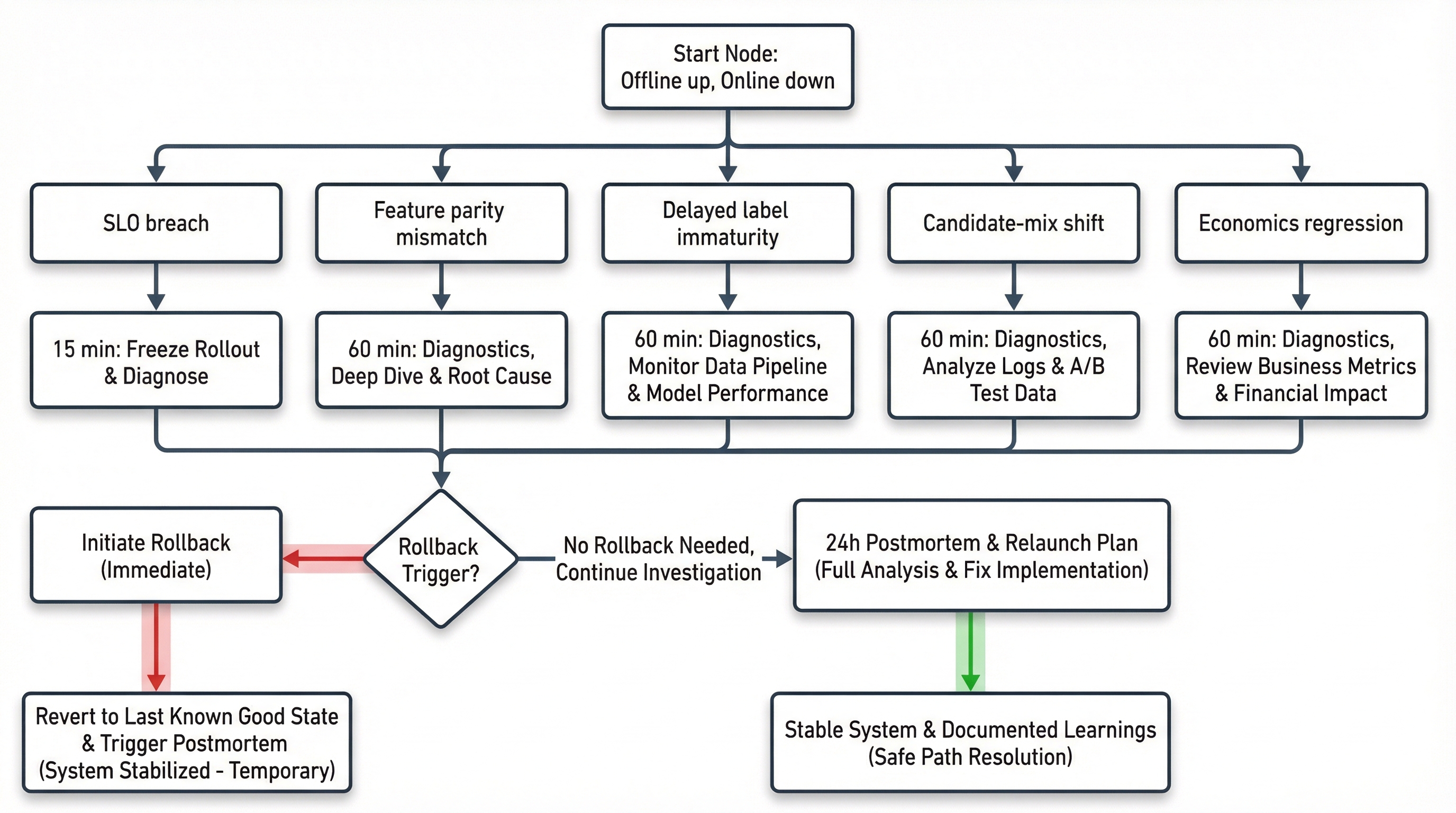
Дерево решений для инцидента: что проверить в первые 15 минут, 60 минут и 24 часа, чтобы быстро локализовать причину и безопасно восстановить систему.
Первые 15 минут
- Заморозить текущий rollout.
- Зафиксировать
policy_id,model_version, время начала деградации. - Проверить системную деградацию: latency, errors, timeouts.
- Переключить мониторинг на сравнение с предыдущей стабильной policy.
Первые 60 минут
- Проверить parity train/serve на live snapshot.
- Проверить состав кандидатов по стадиям.
- Проверить зрелость delayed labels.
- Сверить поведение ключевых cohort.
- Принять решение: rollback или ограниченный срочный фикс.
Первые 24 часа
- Собрать разбор инцидента (postmortem) с корневой причиной.
- Обновить релизные гейты, если выявлен пропуск.
- Обновить контракт сэмплирования/цели/policy.
- Подготовить повторный управляемый rollout.
Для контуров, где рекомендации сочетаются с RAG/tool-calls, дополнительные ограничения и практики разбора инцидентов описаны в материале MLOps для RAG-агента поддержки в 2026: релизы, безопасность и стоимость.
12) Экономика: почему стоимостной гейт обязателен
Главная ошибка в практике: сравнение только cost/request. Для рекомендаций это слишком грубо. Рабочая величина:
Нужно вести минимум два горизонта:
7d: оперативный контроль после релиза;30d: решение об устойчивой экономической целесообразности.
Если качество слегка растет, а cost_per_useful_outcome уходит выше допустимого порога, релиз не считается успешным.
13) Чек-листы
13.1 Pre-release checklist
- Лог-контракт покрывает
propensity,position,feature_snapshot_id,stage. - PIT-correct training dataset верифицирован.
- Train/serve parity в допуске.
- Delayed KPI имеют зрелое окно для решения.
- OPE используется как фильтр кандидатов, а не замена онлайн проверки.
- Shadow и canary готовы, стоп-условия зафиксированы.
- Автооткат протестирован.
- Стоимостной гейт включает
cost_per_useful_outcome.
13.2 Post-release checklist (72 часа)
- Drift/skew под контролем по критичным фичам.
- Calibration и score distribution стабильны.
- Guardrail KPI не деградируют по cohort.
- Stage funnel не показывает скрытых регрессий.
- Стоимостной гейт в допуске на 7d.
13.3 Шаблон записки о решении по релизу (1 страница)
идентификатор_релиза: recsys_ranker_2026_02_26_r3
ответственные: ml-platform + ranking-team
область: home_feed ranking policy
шаг_трафика: 25% -> 50%
гейты:
надежность: зеленая_зона
качество: желтая_зона
экономика: зеленая_зона
известные_риски:
- delayed labels еще не созрели на полном окне
меры_снижения:
- заморозить rollout до закрытия зрелого окна
- усилить cohort-monitoring для новых пользователей
решение: пауза
следующий_пересмотр: 2026-03-02T10:00:00Z
план_отката: rollback_to=feed_rank_v187 rto=10m14) План внедрения 30-60-90
0-30 дней
- Ввести минимальный лог-контракт и parity-проверки.
- Перевести релиз на shadow + canary + rollback.
- Формализовать stop-conditions.
31-60 дней
- Внедрить PIT-валидацию и delayed-label maturity метрики.
- Добавить stage-level attribution дашборды.
- Добавить стоимостной гейт с
cost_per_useful_outcome. - Сверить структуру витрин и фичей с прод-кейсом Поиск и рекомендации для e-commerce, чтобы не размножать несовместимые офлайн/онлайн источники правды.
61-90 дней
- Внедрить цикл повторного прогона и моделирования для риска feedback loops.
- Зафиксировать карту offline -> online предикторов.
- Включить регламент postmortem как часть релизного процесса.
15) Что считать доказательством устойчивого улучшения
Релиз считается устойчиво успешным, если одновременно выполняются условия:
- Offline: прирост на основных и slice метриках без аномальной дисперсии.
- Shadow/Canary: нет нарушения SLO, ограничений и экономики.
- Mature window: delayed KPI подтверждают направление улучшения.
- Stage consistency: локальные улучшения не ломают end-to-end funnel.
- Rollback readiness: проверенный откат в заданный RTO.
Если хотя бы одно условие не выполнено, это не стабильное улучшение, а частичный эксперимент.
16) Типовые анти-паттерны
- Решение только по офлайну без проверки на зрелом окне.
- Нет
propensityв логе, но используются OPE-выводы. - Разный код трансформаций в train и serve.
- CTR объявляется конечной целью без ограничений на прикладные KPI.
- Canary есть формально, но без автостопа и автоотката.
- Считается
cost/request, но неcost_per_useful_outcome.
17) Частые вопросы по offline-online разрыву в RecSys
Почему офлайн метрики растут, а онлайн KPI падают
Потому что офлайн отчет считается на логах старой policy, а после релиза меняется экспозиция и распределение наблюдений. Если не контролировать feedback loops, delayed labels и train-serve skew, офлайн плюс легко превращается в онлайн минус.
Можно ли принимать решение о релизе только по OPE/IPS
Нет. OPE полезен как фильтр кандидатов, но не как единственный гейт. В проде нужны shadow/canary, проверка delayed KPI на зрелом окне и формализованный rollback-контур.
Какой минимальный canary безопасен для deep learning RecSys
Стартовый шаблон 5% -> 25% -> 50% -> 100% обычно достаточен, если есть автостоп, SLO-ограничения, стоимостной гейт и заранее проверенный rollback. Размер шага может быть меньше на критичных поверхностях.
Что важнее: точность модели или экономика
В проде это одна задача. Релиз считается успешным, только если одновременно не деградируют качество, SLO и cost_per_useful_outcome.
18) Связанные материалы
- Контур релизных гейтов и SLO-практик дополняется материалом: MLOps для production ML: 7 релизных гейтов.
- Пример многостадийного retrieval/ranking и работы с DL в рекомендациях: Обучение гибрида LLM и рекомендательной системы на Semantic IDs.
- Для архитектурных компромиссов orchestration-уровня: Агент или workflow: как выбрать архитектуру без хайпа.
- Для практики связки качества и стоимости в проде: MLOps: снижение стоимости ML-пайплайна.
- Для end-to-end контекста поисково-рекомендательной платформы: Поиск и рекомендации для e-commerce.
19) Короткая карточка решения перед 100% rollout
Перед финальным расширением трафика достаточно пройти 6 вопросов:
- Есть ли зрелое окно delayed KPI и оно не противоречит раннему сигналу?
- Прошел ли parity gate для train/serve на live snapshot?
- Есть ли стабильность по cohort/slice, а не только по среднему?
- В норме ли SLO (
p95/p99, timeout, error rate) на текущем шаге canary? - Не вышел ли
cost_per_useful_outcomeза допустимый порог? - Проверен ли rollback на текущей версии и фиксирован ли RTO?
Если на любой вопрос ответ «нет», расширение rollout останавливается до устранения причины.
Итог
Offline-online разрыв в deep learning RecSys это не случайная аномалия, а ожидаемое поведение системы без строгого продового контура. Чем сильнее модель, тем заметнее цена ошибок в данных, логировании, rollout и целевых функциях.
Практический вывод простой: стабильный результат дает не одна модель и не одна метрика, а инженерная дисциплина по всей цепочке.
- корректный лог-контракт;
- контрфактическая оценка с пониманием ограничений;
- point-in-time и train/serve parity;
- релизные гейты с shadow/canary/rollback;
- мониторинг качества, надежности и экономики в едином цикле.
Именно такой контур снижает вероятность ситуации, когда отчет красивый, а продукт после релиза становится хуже.