Evals для LLM-агентов: минимальный набор для продакшна
TL;DR: Evals для агента это инженерный контур с тем же статусом, что контракты инструментов и observability. Рабочий минимум состоит из пяти частей: capability-набор по целевым сценариям, регрессионный набор из реальных инцидентов, проверки траектории на уровне tool calls, откалиброванный LLM-as-judge и онлайн-мониторинг на сэмпле трафика. Надежность измеряется через pass^k, экономика через cost_per_success, релиз блокируется гейтом при нарушении порогов, а источником новых задач служат production-логи и инциденты.
Команды охотно спорят о выборе модели и фреймворка оркестрации, но реже фиксируют ответ на главный вопрос: как именно система узнает, что агент стал хуже. Без evals этот ответ выглядит как “пользователи пожаловались” или “инцидент в пятницу вечером”. Оба варианта стоят дорого: по отраслевым опросам 2025-2026 годов качество остается барьером номер один для вывода агентных систем в прод, а значительная часть проектов закрывается до релиза именно из-за неуправляемого качества.
Этот материал закрывает практическую рамку: какие классы отказов существуют, какие грейдеры их ловят, какими метриками измерять надежность, как устроен eval-харнесс и как собрать контур, без которого агент в прод выходить не должен. Рамка дополняет фреймворк выбора между агентом и workflow: там решался вопрос архитектуры, здесь решается вопрос контроля качества выбранной архитектуры.
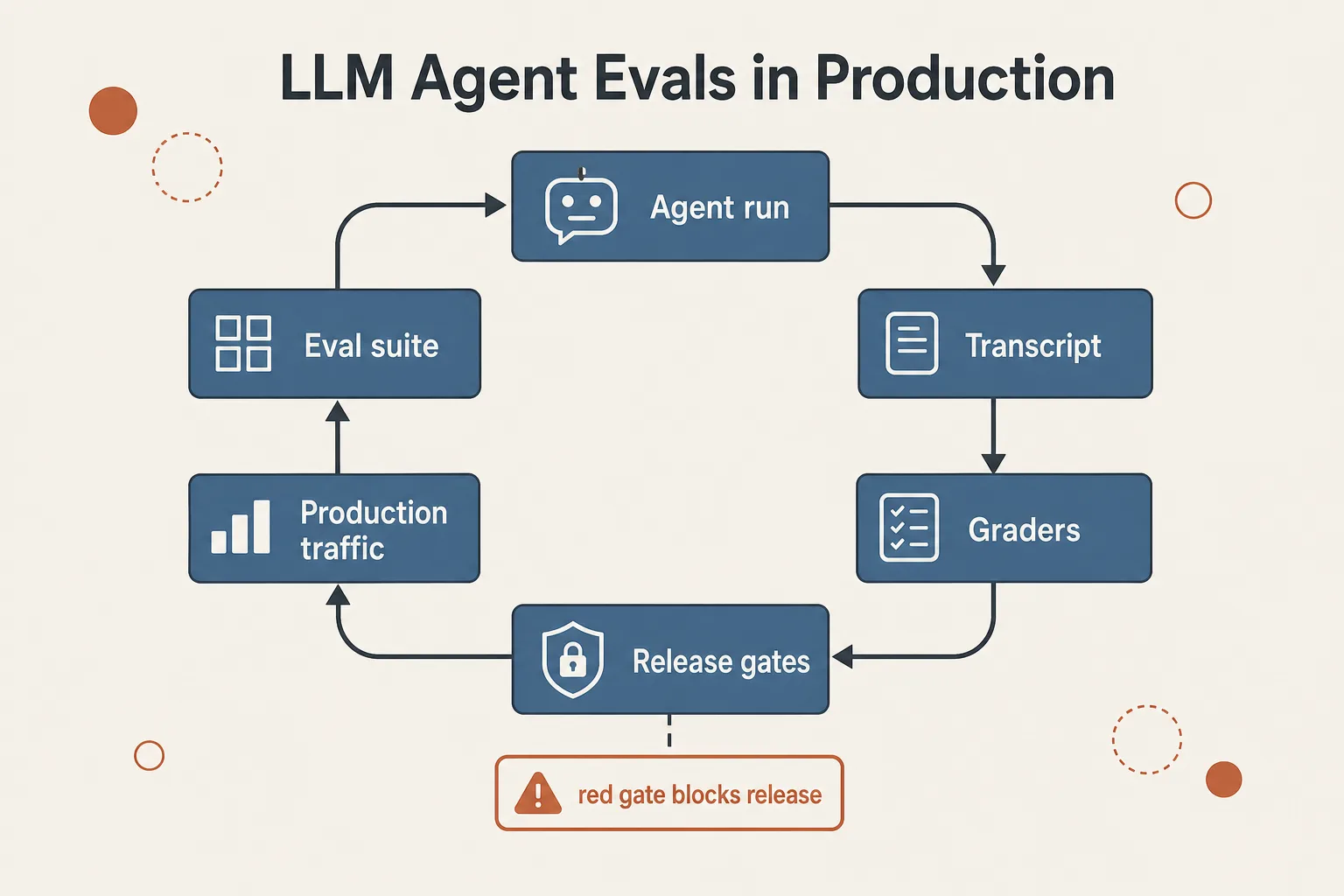
Замкнутый контур качества: eval-набор питает прогоны, грейдеры питают гейты, production возвращает новые задачи в набор.
Как читать этот материал
- Если нужен состав минимального набора: разделы про пять компонентов и архитектуру харнесса.
- Если нужны метрики для релизных решений: разделы про pass@k, pass^k и релизные гейты.
- Если болит доверие к модельному судье: раздел про калибровку LLM-as-judge.
- Если набор уже есть, но устаревает: разделы про задачи из production-логов и чеклист перед релизом.
Словарь: четыре термина, которые убирают путаницу
Обсуждение evals часто буксует из-за терминов. Полезно зафиксировать четыре понятия.
- Task: конкретный сценарий с входом, окружением и критериями успеха. Например: “пользователь просит вернуть заказ, агент должен оформить возврат и не выдать чужие данные”.
- Trial: один прогон агента по задаче. Из-за стохастичности модели одна задача прогоняется несколько раз.
- Transcript (он же trace или trajectory): наблюдаемая запись прогона: сообщения, tool calls с аргументами и результатами, подтянутый контекст, промежуточные артефакты и финальный ответ. Скрытые рассуждения модели в современных системах часто недоступны для логирования или сознательно не логируются, поэтому контур оценки строится на наблюдаемом trace и не должен зависеть от внутреннего chain-of-thought.
- Grader: логика, которая оценивает часть транскрипта или итог. У одной задачи может быть несколько грейдеров, каждый с несколькими проверками.
Точная фиксация этих понятий сразу разводит два разных вопроса: “агент решил задачу” и “агент решил задачу приемлемым способом”. Production-система обязана отвечать на оба.
Карта отказов: что именно должны ловить evals
Прежде чем строить набор, полезно зафиксировать, от чего он защищает. Каждый класс отказа ловится своим компонентом контура, и это главный аргумент против сокращения состава.
| Класс отказа | Как выглядит в продукте | Как выглядит в метриках | Какой компонент ловит |
|---|---|---|---|
| Неверный выбор инструмента | Агент отвечает из памяти вместо обращения к API | падение tool_call_recall |
trajectory-проверки |
| Дрейф аргументов | Вызовы перестают проходить валидацию после смены промпта | рост schema violations | trajectory-проверки |
| Циклы и лишние итерации | Задача решается за 14 шагов вместо 4 | рост steps_per_success и стоимости |
trajectory-проверки |
| Игнорирование результата инструмента | Агент получил данные и ответил из галлюцинированной памяти | расхождение judge groundedness и outcome | judge + trajectory |
| Небезопасный промежуточный шаг | Финал корректен, но по пути читались чужие данные | allowlist violations при зеленом outcome | trajectory-проверки |
| Деградация на длинном горизонте | Качество падает после N-го хода диалога | падение pass rate на многоходовых задачах | capability-набор |
| Тихая регрессия после апдейта модели | Провайдер обновил модель, поведение поплыло | красная регрессия при зеленых демо | регрессионный набор |
| Дрейф судьи | Оценки судьи разошлись с человеческими | падение judge_agreement |
калибровка judge |
Строки таблицы удобно использовать как чеклист при проектировании: если для класса отказа нет компонента, который его ловит, отказ будет обнаружен пользователем.
Два уровня оценки: outcome и trajectory
Outcome-оценка отвечает на вопрос продукта: задача решена или нет. Возврат оформлен, тикет создан, ответ корректен. Это обязательный уровень, но его недостаточно.
Trajectory-оценка отвечает на вопрос инженерии: почему агент сделал то, что сделал. Она смотрит на промежуточные шаги: выбор инструментов, аргументы вызовов, использование результатов, циклы и лишние итерации. Именно здесь видны деградации, которые outcome-метрика маскирует: агент решает задачу за 14 вызовов вместо 4, игнорирует результат инструмента и опирается на галлюцинированную память, или делает небезопасный промежуточный шаг при корректном финале.
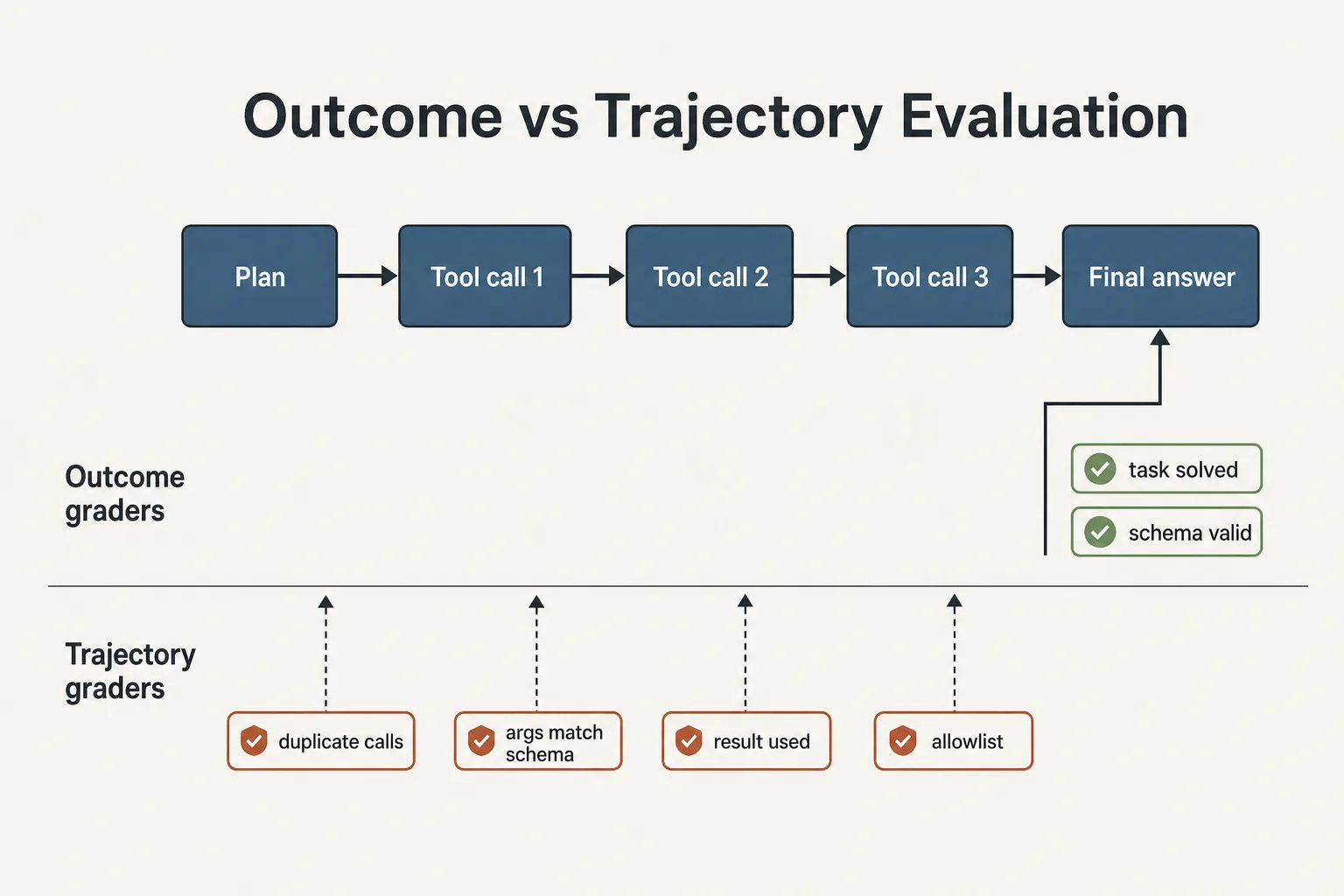
Outcome-грейдеры оценивают финал, trajectory-грейдеры оценивают путь: дубли вызовов, соответствие аргументов схеме, использование результатов и allowlist.
Практическое следствие: оба уровня работают параллельно. Outcome определяет, можно ли релизить. Trajectory определяет, где чинить и что попадет в инцидент через месяц.
Типы грейдеров и когда какой выбирать
Агентные evals комбинируют три типа грейдеров. Порядок предпочтения фиксированный: детерминированные проверки везде, где возможно, модельные там, где детерминизм недостижим, человеческие точечно для калибровки.
| Тип | Что проверяет | Сильные стороны | Ограничения |
|---|---|---|---|
| Code-based | Схемы, статусы, тесты, regex, latency, бюджет вызовов | Дешево, быстро, воспроизводимо | Покрывает только формализуемые свойства |
| Model-based (LLM-as-judge) | Качество ответа, обоснованность, тон, полноту | Масштабируется на субъективные критерии | Требует калибровки, может ошибаться системно |
| Human | Спорные кейсы, эталонная разметка | Источник истины для калибровки | Дорого, медленно, не масштабируется |
Для каждой задачи скоринг собирается из грейдеров одним из способов: бинарно (все грейдеры должны пройти), взвешенно (сумма очков выше порога) или гибридно. Для side-effect действий агента работает только бинарный режим: частично корректный возврат денег это инцидент, а не 0.7 балла.
Отдельное требование к любому грейдеру: устойчивость к обыгрыванию. Если агент может пройти проверку без решения задачи, метрика измеряет качество лазейки. Поэтому грейдеры проектируются так, чтобы прохождение требовало именно решения: проверка состояния окружения после прогона надежнее проверки текста ответа.
Подробный разбор подхода с примерами eval-спек есть в инженерном материале Anthropic Demystifying evals for AI agents. Его стоит прочитать целиком: это один из немногих текстов, где грейдеры разобраны на уровне практики, а не лозунгов.
Минимальный production-набор: пять компонентов
Ниже состав, который закрывает базовый контроль качества агента. Сокращать его опасно: карта отказов выше показывает, какой класс проблем останется невидимым при выпадении каждого компонента.
1) Capability-набор
Задачи по целевым сценариям бизнес-функции с однозначными критериями успеха. Рабочий ориентир для старта: 20-50 задач, но это эвристика, а не стандарт. Узкому scoped-агенту хватит меньшего, критичная enterprise-функция потребует сотен задач, и реальный размер определяется покрытием карты отказов, а не круглым числом.
Хорошая задача проходит тест двух экспертов: оба независимо ставят одинаковый вердикт pass/fail. Если эксперты расходятся, задача дает шум вместо сигнала и требует уточнения.
Для каждой задачи полезно иметь reference solution: эталонный прогон, который проходит все грейдеры. Это доказывает, что задача решаема и грейдеры настроены корректно. Нулевой pass rate на десятках trial почти всегда означает сломанную задачу, а не слабого агента: типичные причины это неоднозначная формулировка, грейдер с жесткой проверкой формата или окружение, в котором задача физически нерешаема.
Состав набора стратифицируется по критичности: critical-сценарии (деньги, доступы, необратимые действия) получают больше задач и больше прогонов, чем периферийные.
2) Регрессионный набор
Каждый production-инцидент и каждый подтвержденный баг превращается в задачу регрессионного набора. Со временем capability-задачи с высоким pass rate тоже “выпускаются” в регрессию: их вопрос меняется с “умеем ли вообще” на “умеем ли все еще стабильно”.
Регрессионный набор запускается на каждое изменение: новый промпт, новая версия модели, новый инструмент, изменение контекстной сборки. Это первая линия защиты от тихих деградаций, включая случай, когда провайдер обновляет модель без смены имени.
3) Проверки траектории
Минимальный состав детерминированных проверок поверх транскрипта:
- соответствие аргументов tool calls целевой JSON-схеме;
- отсутствие дублирующихся вызовов одного инструмента с теми же аргументами;
- бюджет итераций и токенов на задачу;
- использование результата инструмента в следующем шаге планирования;
- отсутствие вызовов вне allowlist и обращений к запрещенным ресурсам.
Контрактная часть этого списка уже разбиралась в материале про tool calling в поисковом контуре: слабые контракты на границе инструментов остаются главным источником агентных инцидентов.
4) Откалиброванный LLM-as-judge
Модельный судья оценивает то, что не формализуется кодом: полноту ответа, обоснованность утверждений, качество коммуникации. Правила, которые отделяют рабочего судью от генератора случайных оценок, собраны ниже в отдельном разделе.
5) Онлайн-мониторинг
Offline-набор не покрывает дрейф реального трафика. Поэтому те же грейдеры запускаются асинхронно на сэмпле живых сессий: обычно 1-10% трафика без блокировки ответа пользователю. Ключевое требование: rubric судьи и пороги совпадают с offline-контуром, иначе pre-launch и post-launch цифры нельзя сравнивать.
Сэмплирование делается стратифицированным: critical-сценарии и сессии с эскалацией попадают в выборку с повышенным весом. Равномерный сэмпл по всему трафику переоценивает легкие сценарии и пропускает деградацию в дорогих.
Архитектура eval-харнесса
Контур из пяти компонентов опирается на одинаковую инфраструктуру. Минимальная архитектура выглядит так:
Task Store ----> Environment ----> Runner ----> Transcript Store ----> Grader Pool ----> Report / Gates
(specs, Manager (agent, (observable (code checks, (dashboards,
fixtures, (state reset, pinned traces, judges, run diffs,
reference frozen clock, versions, OTel attributes, metrics) CI status,
solutions) tool sandbox) parallelism) retention) alerts)
^ |
| v
Production Logs <---- Incident / Feedback Mining <---- Online MonitoringДальше по компонентам: что каждый из них обязан уметь и где команды чаще всего срезают угол, за который потом платят.
Task Store: задачи как код
Спеки задач живут в репозитории и проходят ревью, как обычный код: версия, владелец, история изменений. Изменение критериев успеха задачи это изменение контракта качества, и оно должно быть видно в diff, а не происходить молча в админке.
Вместе со спекой версионируются фикстуры и reference solution. Без этого невозможно ответить на вопрос “метрика упала, потому что агент стал хуже, или потому что кто-то поменял задачу”.
Environment Manager: детерминизм как контракт
Если окружение плавает, метрики измеряют окружение. Минимальные требования:
- фикстуры с фиксированным состоянием и явной версией;
- замороженное время: задачи с дедлайнами и расписаниями не должны зависеть от даты прогона;
- полный сброс состояния между trial: общий state превращает независимые прогоны в зависимые;
- зафиксированные версии инструментов в sandbox.
Для самих инструментов есть три режима с разными trade-off. Моки дешевы и быстры, но скрывают расхождения контрактов с реальным API. Staging-инструменты честнее, но медленнее и требуют изоляции данных. Replay-режим, когда записанные ответы реальных API проигрываются повторно, дает баланс: честные контракты при детерминизме и нулевой нагрузке на внешние системы. Рабочая комбинация: моки или replay в смоук-наборе на каждый коммит, staging в ночном полном прогоне.
Runner: версии прибиты гвоздями
Результат eval-прогона имеет смысл только как точка в пространстве версий. Минимальный кортеж, который сохраняется с каждым прогоном:
run_id
agent_version # код оркестратора
prompt_version # системный промпт и шаблоны
model_id + snapshot # точная версия модели, не алиас "latest"
tools_version # версии контрактов инструментов
fixtures_version # состояние окружения
grader_versions # версии всех грейдеров и rubric
judge_model_id # модель судьи отдельно от модели агентаЕсли хотя бы одно поле не зафиксировано, сравнение двух прогонов теряет смысл: невозможно атрибутировать дельту метрики конкретному изменению. Алиасы вроде “latest” в раннере запрещены по той же причине, по которой они запрещены в production-деплое.
Раннер также отвечает за параллелизм с лимитами на стоимость, таймауты на trial и разделение понятий retry и trial: повторный запуск из-за инфраструктурной ошибки (таймаут API, 500 от sandbox) не считается неуспешным trial и помечается отдельно.
Transcript Store: наблюдаемый trace как первоклассный артефакт
Запись прогона сохраняется в том же формате, что production-трейсы. Для агентных систем удобно опираться на OpenTelemetry GenAI semantic conventions: eval-результаты и боевые трейсы живут в одной системе координат, и грейдер из CI без изменений работает на production-сэмпле.
Состав наблюдаемого trace: сообщения, tool calls с аргументами и результатами, подтянутый контекст, промежуточные артефакты, финальный ответ, тайминги и стоимость по шагам. Скрытые рассуждения модели в этот контракт сознательно не входят: они не всегда доступны, их формат не стабилен между версиями моделей, и грейдер, который зависит от внутреннего chain-of-thought, сломается при следующем апдейте провайдера.
Отдельно фиксируются retention и доступ: транскрипты содержат данные фикстур и потенциально фрагменты production-кейсов, поэтому на хранилище распространяются те же правила, что на логи с пользовательскими данными.
Grader Pool: грейдеры отделены от раннера
Один транскрипт можно переоценить новой версией грейдера без повторного прогона агента. Это резко удешевляет итерации на rubric: пересмотр порога или формулировки не требует тратить бюджет на прогоны, а историю можно пересчитать задним числом и посмотреть, как новая rubric оценила бы прошлые релизы.
Следствие для дизайна: грейдер получает на вход только транскрипт и состояние окружения после прогона. Грейдер, которому нужен живой доступ к агенту, спроектирован неправильно.
Report и гейты: diff важнее снапшота
Агрегированная метрика прогона скрывает структуру изменений. Рабочий отчет сравнивает два прогона на уровне задач: какие задачи перешли из pass в fail, какие из fail в pass, где выросла дисперсия. Релиз, который поднял средний pass rate на два пункта, но уронил три critical-задачи, виден только в таком diff.
Поэтому минимальный набор представлений: тренд по дням, diff двух прогонов по задачам, разбивка по критичности сценариев и стоимость прогона. Этого достаточно, чтобы гейты из раздела ниже работали на данных, а не на ощущениях.
Сколько прогонов нужно: статистика без иллюзий
Стохастичность агента делает одиночный прогон бессмысленным измерением, но и бесконечный бюджет на прогоны не нужен. Важно понимать, что именно покупается за каждый trial.
Погрешность оценки pass rate подчиняется биномиальной статистике: стандартная ошибка равна sqrt(p(1-p)/n). Конкретные следствия:
- 5 trial на одну задачу при истинном pass rate 0.8 дают стандартную ошибку около 18 процентных пунктов: на уровне задачи различимы только грубые состояния “стабильно проходит”, “стабильно падает”, “нестабильна”;
- 40 задач по 5 trial дают 200 наблюдений и ошибку среднего по набору около 3 пунктов: этого хватает для трендов и гейтов с запасом от порога;
- сужение интервала вдвое требует вчетверо больше прогонов, поэтому “добавим точности” всегда стоит дорого.
Из этого следуют три практических правила. Первое: гейт, который сравнивает метрику с порогом, должен учитывать неопределенность. Если результат лежит в пределах ошибки от порога, решение принимается не подбрасыванием монеты, а добавлением прогонов на спорных задачах. Второе: при сравнении двух версий агента работает парное сравнение на одинаковых задачах и фикстурах: дельта по парам имеет меньшую дисперсию, чем разница двух независимых средних, и требует заметно меньше прогонов для того же вывода. Третье: на малых n для интервалов корректнее консервативные оценки вроде интервала Вилсона, потому что нормальное приближение на 5 trial завышает уверенность.
Бюджет прогонов распределяется по критичности: 1-3 trial на задачу в смоук-наборе на каждый коммит, 5-10 trial на critical-сценариях в ночном прогоне и перед релизом, дополнительные прогоны точечно там, где метрика уперлась в порог гейта.
Нестабильные задачи не удаляются из набора: флапающая задача это сигнал о реальной нестабильности агента на сценарии. Она получает владельца и срок разбора, а до разбора учитывается отдельной строкой отчета, чтобы не шуметь в гейтах.
Метрики надежности: pass@k против pass^k
Рабочая пара метрик для стохастической системы:
- pass@k: вероятность хотя бы одного успеха за k попыток. Подходит для инструментов, где одна удачная попытка решает задачу: генерация кода с тестами, исследовательский поиск.
- pass^k: вероятность успеха во всех k попытках подряд. Подходит для пользовательских агентов, где важна повторяемость поведения.
Разница принципиальная. Агент с per-trial успехом 75% дает pass^3 около 42%: 0.75 в кубе. Для customer-facing функции это означает, что больше половины пользователей при трех обращениях хотя бы раз получат отказ. Outcome-метрика “75% задач решается” звучит приемлемо, pass^k показывает реальную картину надежности. С ростом k метрики расходятся в противоположные стороны: pass@k стремится к 100%, pass^k падает к нулю, и выбор между ними определяется продуктовым требованием, а не вкусом.
К паре надежности добавляются метрики экономики и процесса:
task_success_rate # outcome по целевым сценариям
pass^k # стабильность на k прогонах
tool_call_precision # доля корректных вызовов среди сделанных
tool_call_recall # доля нужных вызовов, которые агент сделал
steps_per_success # медиана шагов до успеха
cost_per_success # полная стоимость на успешную задачу
judge_agreement # согласованность судьи с человеческой разметкойФормула стоимости та же, что использовалась в разборе выбора архитектуры: числитель собирает LLM, инструменты, инфраструктуру и человеческий контроль, знаменатель считает только успешные задачи.
LLM-as-judge без самообмана
Модельный судья это самый частый источник ложной уверенности в агентных системах. Наивная схема “попроси модель оценить от 1 до 10” дает оценки, которые не коррелируют с качеством. Рабочий набор правил:
- Калибровка на людях до масштабирования. Судья запускается на эталонном наборе с человеческими метками. Рабочий ориентир согласованности: 75-90%, но это эвристика, которую калибрует сам домен. На неоднозначных задачах, где и эксперты расходятся, 75% может быть потолком, на формализуемых критериях 90% это минимум. Честная процедура: сначала измерить согласованность экспертов между собой, затем требовать от судьи сопоставимого уровня. Судья без измеренной согласованности это генератор шума с уверенным тоном.
- Один судья на одно измерение. Вместо одной оценки “за все” каждый критерий (обоснованность, полнота, тон) получает изолированного судью со своей rubric. Смешанные оценки не диагностируются.
- Структурная rubric с порогами. Явные уровни и признаки каждого уровня. Расплывчатая rubric дает несогласованные вердикты так же, как расплывчатая задача дает шумный pass rate.
- Выход “Unknown”. Судье явно разрешено ответить “недостаточно информации”. Это снижает галлюцинированные вердикты на кейсах вне rubric.
- Доказательства до оценки. Судья сначала цитирует фрагменты транскрипта, затем выносит вердикт. Порядок имеет значение: оценка без принуждения к доказательствам деградирует к общим впечатлениям.
- Перекалибровка по расписанию. Смена модели судьи, промпта или продуктовых требований обнуляет старую калибровку.
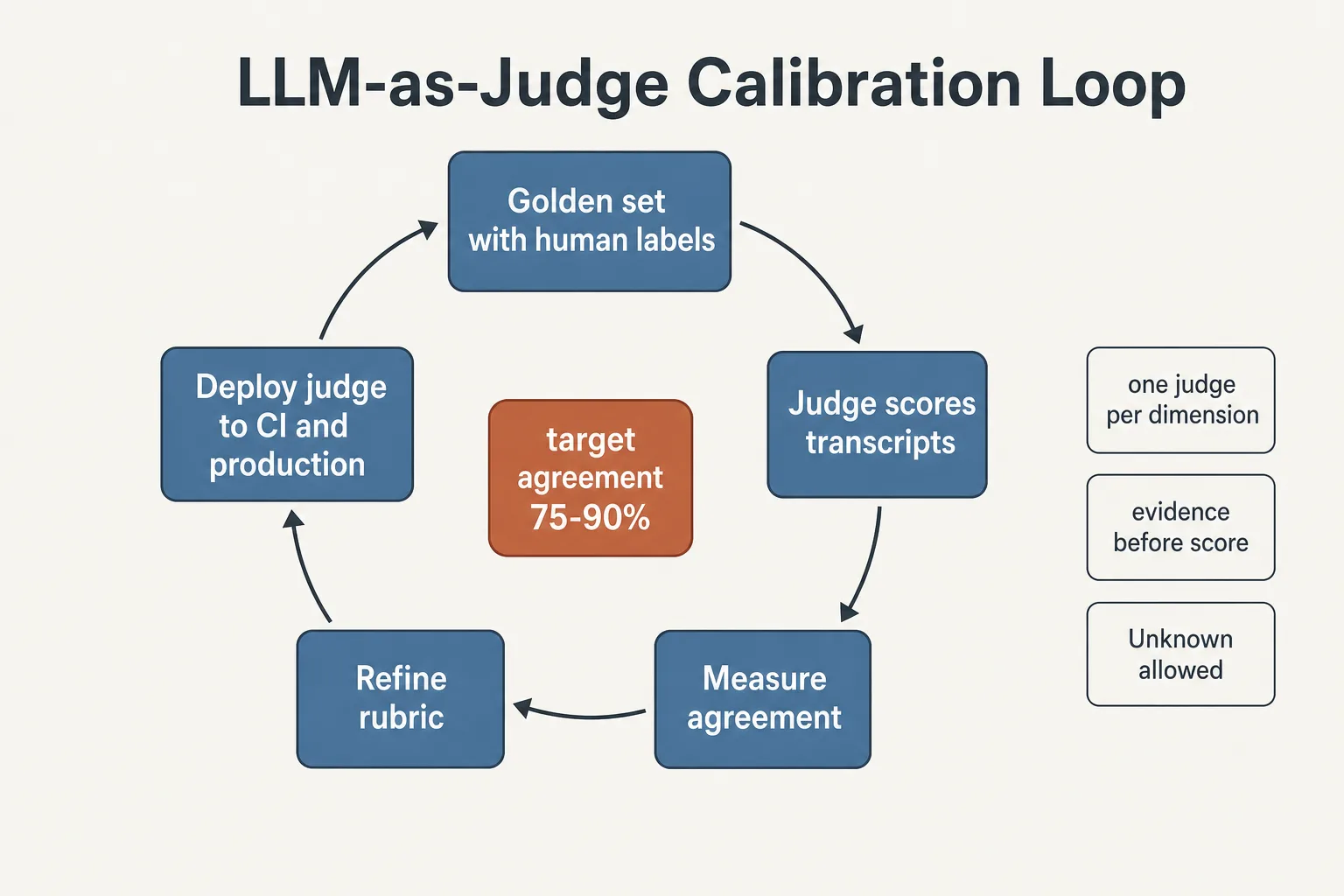
Судья допускается к релизным решениям только после измеренной согласованности с экспертами и переоценивается по расписанию.
Скелет промпта судьи, который реализует правила 3-5:
Роль: оценщик качества ответов агента поддержки.
Измерение: groundedness (только оно).
Rubric:
1.0 каждое фактическое утверждение подтверждено данными
из tool results в транскрипте
0.5 утверждения подтверждены частично, есть неподтвержденные детали
0.0 ключевые утверждения не подтверждены данными транскрипта
Unknown в транскрипте недостаточно информации для вердикта
Формат ответа:
evidence: [цитаты из транскрипта]
score: <1.0 | 0.5 | 0.0 | Unknown>
reason: <одно предложение>При измерении согласованности стоит помнить про дисбаланс классов: если 90% эталонных кейсов имеют метку pass, судья, который всегда отвечает pass, покажет 90% совпадения. Поэтому согласованность считается отдельно по классам pass и fail, и порог должен выполняться на обоих.
У модельных судей есть и документированные систематические смещения. Лучше всего изучен position bias в парных сравнениях: вердикт меняется от перестановки кандидатов местами, что подтверждено систематическим исследованием position bias в LLM-as-judge. Туда же относятся склонность к многословным ответам и завышение оценок выходам собственного семейства моделей. Практические контрмеры: оценивать кандидатов независимо по rubric вместо парных сравнений, а там, где парное сравнение необходимо, прогонять обе перестановки и считать расхождение вердиктов сигналом ненадежности кейса.
Отдельная дисциплина: периодическое чтение транскриптов руками. Когда задача падает, транскрипт показывает, ошибся агент или грейдер отклонил валидное решение. Команды, которые не читают транскрипты, со временем оптимизируют систему под ошибки собственных грейдеров.
Задачи из production-логов: контур пополнения
Набор, который не пополняется, устаревает за квартал. Самый дешевый источник новых задач это production-логи: неуспешные сессии, эскалации к человеку, повторные обращения по той же проблеме и сессии с аномальной длиной траектории.
Рабочий цикл пополнения:
- Отбор кандидатов по сигналам: эскалация, негативный фидбек, аномальное число шагов, нарушение бюджета.
- Кластеризация похожих отказов, чтобы не плодить дубли задач.
- Превращение кластера в eval-задачу: вход, фикстуры окружения, критерии успеха, reference solution.
- Анонимизация: в фикстуры попадают синтетические данные с сохранением структуры кейса.
Инженерная сторона этого конвейера разбиралась в материале про продуктовые логи как данные для post-training: контуры почти идентичны, меняется только потребитель. Один и тот же пайплайн отбора и очистки логов способен питать и дообучение, и eval-набор, и это сильный аргумент строить его как общую инфраструктуру.
Артефакт: eval-спека задачи и релизный гейт
Минимальная спека задачи, которая связывает грейдеры, метрики и пороги в одном файле:
task_id: refund_flow_037
owner: support-agent-team
scenario: "Возврат заказа с частичной оплатой бонусами"
environment:
fixtures: refund_sandbox_v3
tools: [orders_api, refund_api, customer_api]
clock: "2026-06-09T10:00:00Z"
trials: 5
graders:
- type: code
checks:
- refund_created: true
- refund_amount_matches_policy: true
- no_pii_in_response: true
- tool_args_match_schema: true
- max_tool_calls: 6
- type: judge
rubric: support_answer_quality_v2
dimensions: [groundedness, completeness]
threshold: 0.8
scoring: binary
pass_requirement: "pass^5 >= 0.8"
reference_solution: transcripts/refund_flow_037_reference.jsonРелизный гейт поверх набора таких задач:
release_id: support_agent_2026_06_09_r1
gates:
capability_suite: "task_success_rate >= 0.85"
regression_suite: "pass rate = 1.0"
reliability: "pass^3 >= 0.7 на critical-сценариях"
trajectory: "schema violations = 0, allowlist violations = 0"
judge_calibration: "judge_agreement >= 0.8, проверено <= 30 дней назад"
economics: "cost_per_success <= baseline * 1.15"
decision_rule: "любой красный гейт блокирует промоут"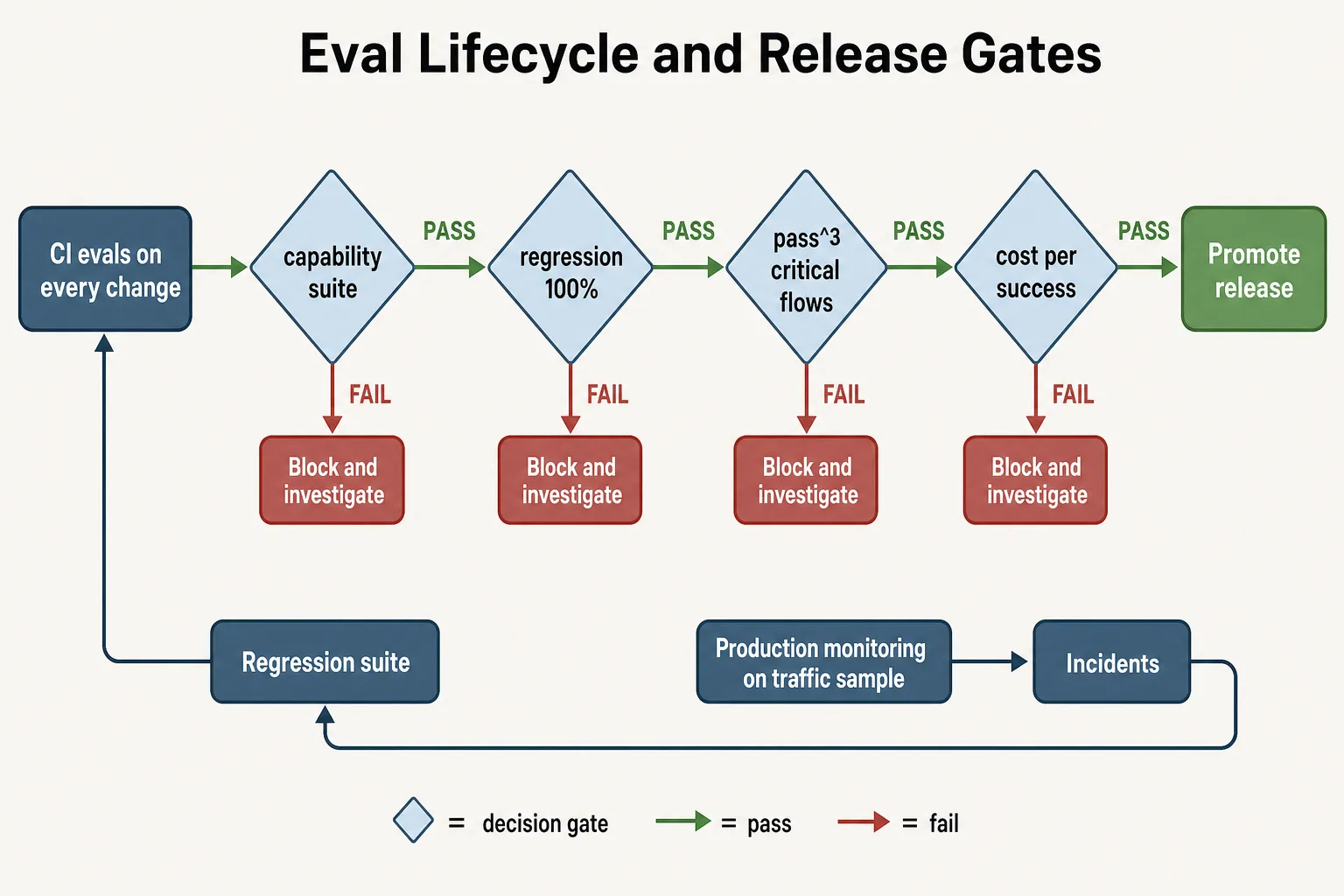
Каждый гейт имеет бинарное решение: красный статус блокирует промоут, а мониторинг и инциденты возвращают новые задачи в регрессионный набор.
Структура гейтов сознательно повторяет подход из материала про релизные гейты для production ML: меняется состав проверок, дисциплина остается той же. Для RAG-агентов состав гейтов с поправкой на безопасность и стоимость разбирался в отдельном production-разборе.
Где evals живут в жизненном цикле
Каждый метод оценки работает на своей стадии, подменять их друг другом не получается.
- На каждый коммит. Смоук-набор: 10-15 задач, 1-3 trial, только code-based грейдеры. Бюджет: минуты и единицы долларов. Цель: поймать грубую поломку до merge.
- Ночной прогон. Полный capability и регрессионный наборы, 5-10 trial на critical-сценариях, судьи включены. Цель: тренд качества по дням и ранний сигнал дрейфа.
- Релиз. Гейты из предыдущего раздела. Красный гейт блокирует промоут без обсуждений.
- Production. Асинхронный мониторинг на стратифицированном сэмпле трафика плюс A/B на значимых изменениях, когда трафика достаточно.
- Постоянный фон. Триаж пользовательского фидбека, еженедельное чтение сэмпла транскриптов, перенос новых отказов в регрессионный набор, перекалибровка судей по расписанию.
Этот цикл структурно совпадает с контуром, который разбирался для offline-online разрыва в RecSys: offline-метрики предсказывают онлайн-поведение только при дисциплине логирования и регулярной сверке. Агентные системы наследуют ту же проблему в более острой форме, потому что пространство действий шире.
Публичные бенчмарки в этом цикле занимают скромное место. Наборы вроде tau2-bench полезны для сравнения базовых моделей на типовых многоходовых tool-use сценариях: методология опубликована и проверяема. Доменный набор они при этом не заменяют по двум методологическим причинам. Первая: корреляция общего бенчмарка с конкретной бизнес-функцией не гарантирована и сама требует проверки. Вторая: публичные наборы со временем попадают в обучающие данные и в целевые ориентиры разработки моделей, поэтому рост публичного скора без роста на доменном наборе это известный паттерн, а не аномалия.
Анти-паттерны
- Pass rate 100% как цель. Набор, который всегда зеленый, перестал тестировать систему. Строгий набор с pass rate 60-80% информативнее идеальных отчетов.
- Неоткалиброванный судья в гейтах. Решения о релизе принимаются по метрике, у которой не измерена согласованность с людьми.
- Только outcome-метрики. Деградации траектории накапливаются невидимо: рост числа шагов, лишние вызовы, игнорирование результатов инструментов.
- Оценка по среднему вместо pass^k. Средний success rate скрывает нестабильность, которую пользователь видит как лотерею.
- Eval-набор без владельца. Набор, который не пополняется из инцидентов, устаревает за квартал и создает ложное чувство контроля.
- Грейдеры, которые можно обыграть. Если агент проходит проверку без решения задачи, метрика измеряет качество лазейки.
- Плавающее окружение. Фикстуры без версии, живое время и общий state между trial превращают eval в генератор случайных чисел.
- Разные rubric offline и online. Pre-launch и post-launch цифры перестают сравниваться, и дрейф качества списывается на “специфику трафика”.
Чеклист перед первым релизом с гейтами
Порядок внедрения у каждой команды свой, но проверить контур перед тем, как доверять ему релизные решения, можно одним списком:
- у каждой задачи есть reference solution, и он проходит все грейдеры;
- две независимые разметки экспертов на сэмпле задач совпадают;
- версии модели, промпта, инструментов, фикстур и грейдеров зафиксированы в каждом прогоне;
- окружение детерминировано: сброс состояния, замороженное время, версионированные фикстуры;
- судья откалиброван, согласованность измерена по классам pass и fail отдельно;
- инфраструктурные retry отделены от неуспешных trial;
- отчет умеет diff двух прогонов на уровне задач, а не только средние;
- гейты учитывают статистическую погрешность, спорные случаи добирают прогоны;
- инциденты конвертируются в регрессионные задачи, у набора есть владелец;
- онлайн-мониторинг использует те же rubric и пороги, что offline-контур.
Пункты намеренно проверяемые: каждый либо выполняется, либо нет. Если хотя бы три не выполняются, гейты пока измеряют шум.
Короткий итог
Evals для агента это слой архитектуры с тем же статусом, что контракты инструментов и observability. Минимальный состав: capability-набор, регрессия из инцидентов, проверки траектории, откалиброванный судья и онлайн-мониторинг на едином rubric.
Надежность измеряется через pass^k, экономика через cost_per_success, релиз управляется гейтами с бинарным решением. Источником новых задач служит production: инциденты, фидбек и прочитанные транскрипты.
Система с таким контуром деградирует громко и чинится по данным. Система без него деградирует тихо и чинится по жалобам.
FAQ
Какой минимальный набор evals нужен LLM-агенту перед продом?
Capability-набор по целевым сценариям, регрессионный набор из прошлых инцидентов, проверки траектории на уровне tool calls, откалиброванный LLM-as-judge и онлайн-мониторинг на сэмпле живого трафика.
Чем pass@k отличается от pass^k и когда какой использовать?
pass@k показывает вероятность хотя бы одного успеха за k попыток, pass^k показывает вероятность успеха во всех k попытках подряд. Для пользовательских агентов важнее pass^k: он измеряет стабильность поведения.
Можно ли доверять LLM-as-judge без человеческой разметки?
Нет. Судью калибруют на эталонном наборе с человеческими метками и считают согласованность. Рабочий ориентир: 75-90% совпадения с экспертами до запуска судьи в масштабе.
Сколько прогонов нужно на одну eval-задачу?
Для смоук-проверок в CI достаточно 1-3 прогонов на задачу, для релизных решений по критичным сценариям нужно 5-10. Точность оценки растет как корень из числа прогонов, поэтому бюджет распределяется по критичности.
Что означает pass rate 100% на eval-наборе?
Чаще всего это признак слабого набора, который перестал стресс-тестировать систему. Полезнее держать набор, где строгий грейдер дает 60-80% и показывает реальные зоны деградации.
Откуда брать задачи для eval-набора?
Три источника: целевые сценарии бизнес-функции, production-инциденты и кластеризация неуспешных сессий из логов. Набор без постоянного притока задач из прода устаревает за квартал.