Логи поиска и рекомендаций как данные для LLM post-training
TL;DR: Продуктовые логи не являются готовыми метками. Это трассы, которые появились при конкретной политике поиска, ранжирования, интерфейсе и контуре обратной связи.
Если логировать намерение, набор кандидатов, экспозицию, подтверждающие источники, версии модели и политики, а также отложенные исходы, из логов поиска и рекомендаций можно строить SFT-примеры, DPO-пары, трудные негативные примеры, данные для reward-моделей и промпты/роллауты для GRPO/RL.
Главная инженерная задача: контракт данных. Нужно понять, какие события попадают в слой, готовый к обучению, какие отбрасываются, как это версионируется и как потом связывается с офлайн- и онлайн-качеством.
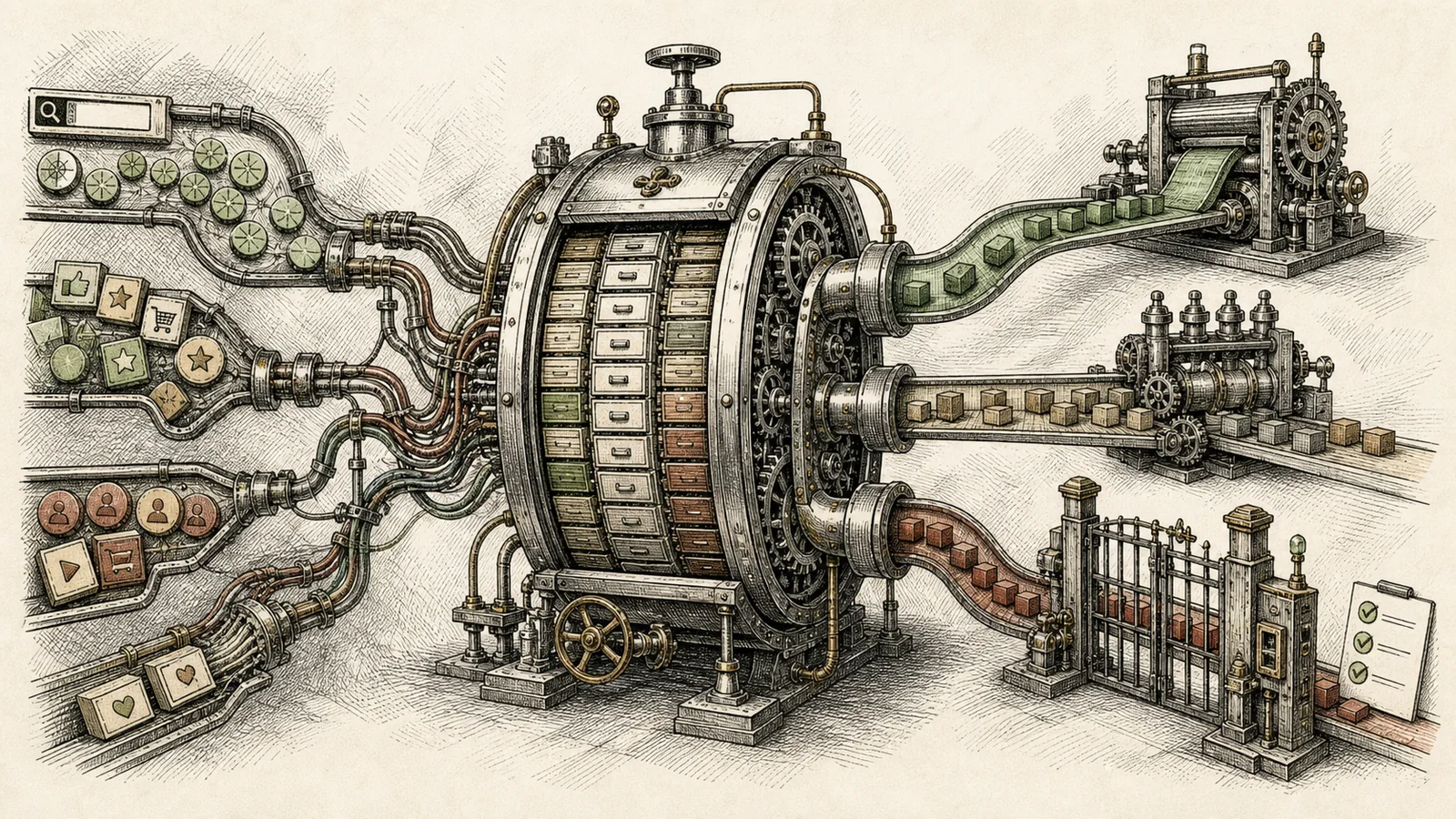
Продуктовые логи как вход в инфраструктуру данных для post-training: события продукта, ядро датасетов, обучение и релизные гейты.
В LLM post-training часто обсуждают методы: SFT, DPO, PPO, GRPO, RLHF. В промышленной системе вопрос обычно быстрее упирается в другой слой: откуда берутся данные, можно ли им доверять, как воспроизвести состав датасета и почему новая модель стала лучше или хуже.
Эта статья разбирает пайплайн данных для LLM post-training поверх продуктовых логов: логи поиска, логи рекомендаций, трассы retrieval и пользовательская обратная связь превращаются в SFT-датасеты, DPO-датасеты, данные для reward-моделей и роллауты GRPO/RL. Фокус статьи: данные, на которых обучающий контур не будет оптимизировать мусор.
В поиске и рекомендательных системах этот слой знаком давно. Рекомендательная система годами учится на логах экспозиции, кликов, пропусков и покупок. Поисковая система живет на запросах, кандидатах, релевантности, переупорядочивании и продуктовых ограничениях. Генеративные модели добавили новый интерфейс, но базовая инженерная задача осталась прежней: превратить шумные события в обучающий сигнал без утечки данных, без самообмана и без разрыва между офлайн-метрикой и онлайн-поведением.
Главная идея:
- Продуктовые логи не являются готовыми метками.
- Продуктовые логи порождаются конкретной политикой логирования.
- Обучающие данные появляются только после восстановления намерения, набора доступных кандидатов, экспозиции, созревшей обратной связи, версии политики и статуса безопасности.
Дальше статья идет в четыре слоя:
- Что логировать: трассу взаимодействия, экспозицию, версию политики.
- Как строить датасеты: SFT, DPO, reward-модель, GRPO/RL.
- Как не сломать качество: трудные негативные примеры, синтетические данные, калибровку модели-судьи, утечки.
- Как выпускать: версионирование, релизные гейты, связь офлайн- и онлайн-метрик, модель стоимости.
Быстрая навигация:
- инженеры данных: “Что является единицей данных” и “Версионирование датасетов”;
- LLM-инженеры: секции про SFT, DPO, reward-модель и GRPO;
- инженеры поиска и рекомендаций: смещения, трудные негативные примеры и связь офлайн- и онлайн-метрик;
- ML-платформа: архитектура, релизные гейты и модель стоимости.
Почему логи поиска и рекомендаций ценны для post-training
У большинства instruction-датасетов есть структурная слабость: они хорошо выглядят как текст, но плохо описывают реальную конкуренцию вариантов. В продуктовых логах эта конкуренция уже есть.
Поисковый лог показывает:
- что пользователь сформулировал;
- как система поняла запрос;
- какие кандидаты были подняты;
- какие документы, товары, изображения или ответы конкурировали;
- что было показано;
- что пользователь выбрал, проигнорировал, исправил или оценил отрицательно.
Рекомендательный лог добавляет последовательность:
- историю взаимодействий;
- контекст сессии;
- экспозицию;
- отложенные исходы;
- контуры обратной связи;
- трудные негативные примеры рядом с правильным выбором.
Для LLM это особенно полезно. Модель учится выбирать между близкими вариантами, объяснять выбор, держать контекст, проверять источники и снижать зависимость от общего знания там, где нужен retrieval.
Связанный пример уже разобран в статье про Semantic IDs и гибрид LLM-рекомендателя: каталог и поведение можно сделать частью языкового интерфейса. Текущий материал смотрит на соседний слой: как готовить данные, чтобы такой интерфейс можно было улучшать системно.
Логи как источник сигналов с системными смещениями
Продуктовые логи дают полезные сигналы, но не дают готовую истину. Клик, пропуск, время просмотра, добавление в корзину и явная оценка были получены при конкретной выдаче, интерфейсе, ранжировании, модели и политике показа. Поэтому логи надо читать как смещенные наблюдательные трассы.
В learning-to-rank эта проблема описана давно. В работе A General Framework for Counterfactual Learning-to-Rank implicit feedback вроде кликов и времени просмотра рассматривается как дешевый и полезный сигнал, но его наивное использование искажает обучение из-за смещения показа. Для LLM post-training это означает прямое правило: предпочтения, выведенные из кликов, можно использовать только вместе с контекстом экспозиции.
Основные смещения в логах поиска и рекомендаций:
| Смещение | Как проявляется | Что логировать |
|---|---|---|
| Смещение наблюдения | модель видит только события, которые произошли при старой политике | policy_version, experiment_id, model_version, index_snapshot |
| Позиционное смещение | верхние результаты получают больше кликов при той же релевантности | rank, viewport_exposure, scroll_depth, exploration bucket, logging policy, known propensity или inputs для ее оценки |
| Смещение отбора | в обучение попадают активные пользователи, популярные товары и частые намерения | surface, segment, intent_class, sampling metadata |
| Смещение популярности | популярный объект становится еще чаще показанным и кликнутым | popularity features, exploration bucket, candidate source |
| Отложенная обратная связь | покупка, удержание или успешное выполнение задачи приходят позже события | label maturation window, attribution timestamp |
| Петля обратной связи | новая политика меняет будущие данные для следующего обучения | dataset version, release version, online cohort |
Эта таблица важнее выбора конкретного обучающего метода. Алгоритм обучения не исправляет плохой сигнал. Он просто оптимизирует его быстрее.
Если в логах клик был следствием позиции, скидки или интерфейса, post-training не отличит это от качества ответа без дополнительных полей.

Позиция и экспозиция: клик появляется внутри конкретной выдачи, видимой области viewport и политики показа.
Что является единицей данных
Главная ошибка: считать единицей данных только “prompt -> answer”. Для post-training на логах поиска и рекомендаций это слишком бедная структура.
Более полезная единица выглядит так:
interaction_id: q_2026_05_28_8841
user_context:
tenant_id: retail_ru
session_id: s_19f2
locale: ru
surface: catalog_search
request:
raw_query: "кроссовки для бега по мокрому асфальту"
normalized_query: "running shoes wet asphalt"
intent_class: product_discovery
retrieval:
policy_id: retrieval_hybrid_v42
query_embedding_model: clip_text_v17
index_snapshot: catalog_index_2026_05_28
candidate_sources:
- bm25
- vector_image_text
- behavioral_recsys
ranking:
ranker_id: ranker_late_v188
shown_items:
- item_id: sku_771
rank: 1
score: 0.84
evidence: ["title", "image", "reviews"]
- item_id: sku_219
rank: 2
score: 0.79
evidence: ["title", "attributes"]
exposure:
viewport_items: ["sku_771", "sku_219"]
scroll_depth_px: 1240
experiment_id: rec_rank_ab_17
outcome:
clicked_item_id: sku_771
skipped_item_ids: ["sku_219"]
dwell_ms: 43120
add_to_cart: true
explicit_feedback: null
versions:
ranking_policy: ranker_late_v188
answer_policy: grounded_answer_v9
safety_policy: safety_filter_v8
quality:
latency_ms: 142
empty_result: false
policy_violation: falseПоле skipped_item_ids в таком логе не должно означать “все кандидаты без клика”. Это производная метка: кандидат был отрисован, попал в видимую область (viewport), имел достаточное время для взаимодействия и прошел окно созревания обратной связи. Остальные кандидаты остаются unseen, not_exposed или not_matured, иначе класс rejected быстро загрязняется.
Если лог-контракт проектируется заранее, полезно проектировать его через сущности. Минимальный набор выглядит так:
| Сущность | Поля |
|---|---|
| Идентификаторы события | event_id, request_id, trace_id, session_id, event_time, ingest_time, source_service |
| Запрос / промпт | raw query, normalized query, language, locale, intent, turn number, previous turns reference |
| Контекст | surface, device class, geo bucket, personalization state, experiment IDs |
| Состояние поиска | retriever version, embedding model, index snapshot, corpus snapshot, query rewrite, filters |
| Набор кандидатов | candidate IDs, ranks, scores, features, source retriever, reranker version |
| Экспозиция | viewport, impression timestamp, visible rank, scroll depth, render status |
| Действия пользователя | click, skip, hover, dwell, save, conversion, reformulation, edit, explicit rating |
| Ответ и источники | generated answer, retrieved docs, citations, tool outputs, accepted answer, user edit diff |
| Политика и безопасность | model version, prompt template, safety filter, refusal category, moderation labels |
| Воспроизводимость | code version, config hash, schema version, data contract version, sampling metadata |
Из такой записи можно собрать несколько типов обучающих объектов.
| Тип данных | Источник в логе | Для чего использовать |
|---|---|---|
| SFT-пример | запрос + правильный ответ/объяснение/источники | Обучить формат ответа и поведение с опорой на источники |
| Пара предпочтений | chosen answer/action против rejected answer/action | DPO, reward modeling или reranking |
| Трудный негативный пример | близкий кандидат, который был показан, но проиграл после валидации | retrieval, ранжировщик, reward-модель |
| Траектория | последовательность query -> retrieve -> rerank -> answer -> feedback | GRPO/online RL и оценки по трассам |
| Задача для модели-судьи | ответ + рубрика + источники + исход | LLM-as-judge и мониторинг качества |
| Регрессионный пример | пример из инцидента или канареечной деградации | Релизные гейты и регрессионные оценки |
Хороший обучающий датасет для LLM должен хранить связь с исходной трассой взаимодействия. Иначе через месяц невозможно понять, почему пример оказался в обучении и какой сигнал он нес.
Архитектура пайплайна
В реальной системе этот пайплайн почти всегда распадается на набор backfill-задач, потоковых обновлений, пакетного инференса, вызовов модели-судьи, очередей ручной проверки и задач релиза датасета. Ошибка в любом месте может выглядеть как “модель стала хуже”, хотя на самом деле изменился состав датасета.
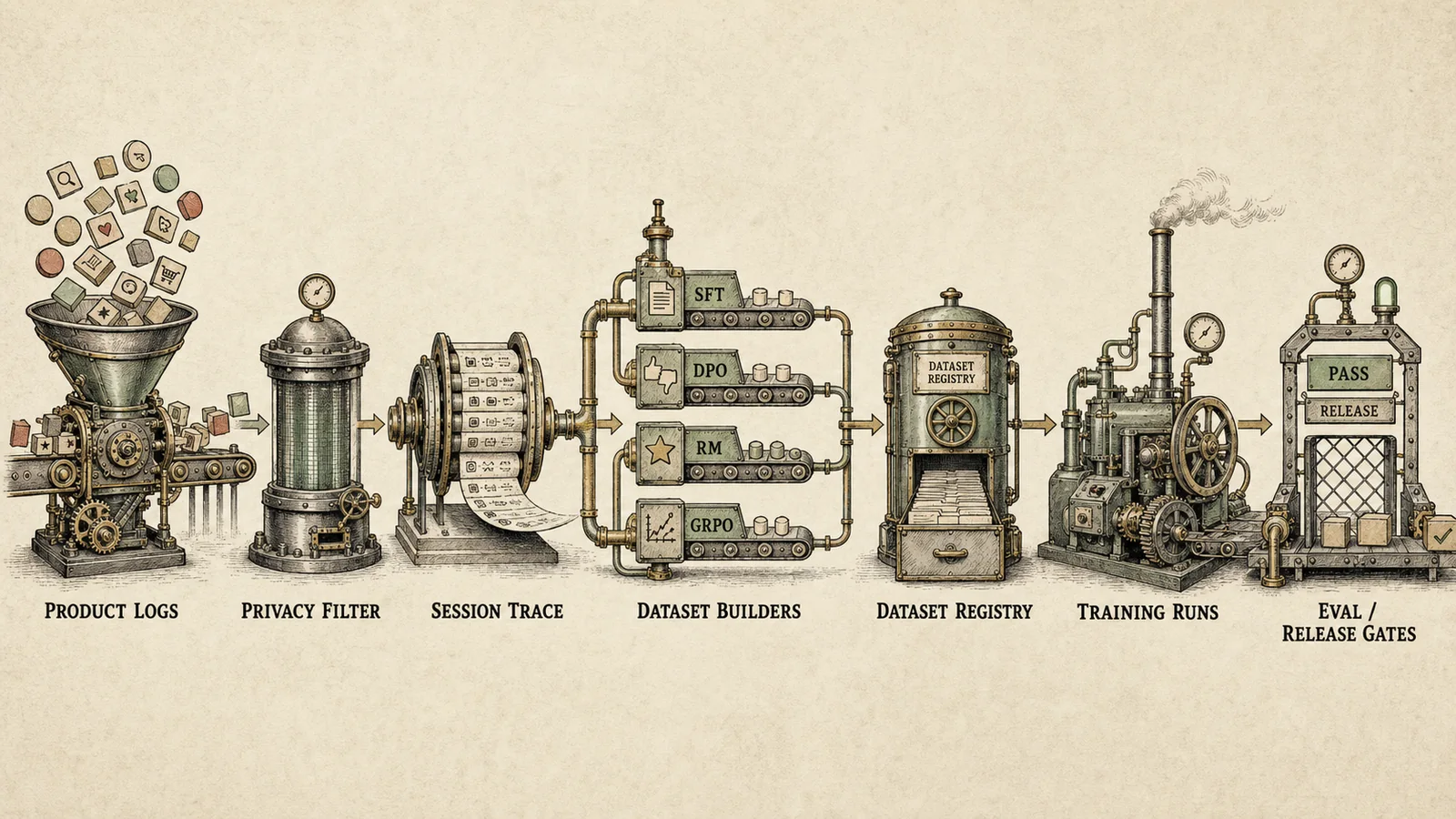
Сквозной пайплайн: продуктовые логи, фильтрация приватных данных, трасса сессии, сборщики датасетов, реестр, запуски обучения и релизные гейты.
Базовый пайплайн можно представить так:
Продуктовые логи
-> нормализация событий
-> фильтрация приватных данных и политик
-> восстановление сессий
-> атрибуция поиска и ранжирования
-> дедупликация и проверка загрязнения бенчмарков
-> майнинг трудных негативных примеров
-> синтетическое расширение
-> валидация моделью-судьей
-> версионирование датасетов
-> экспорты SFT / DPO / GRPO
-> запуск обучения
-> оценки и релизные гейтыНа малом масштабе это можно собрать на пакетных задачах и parquet. На сотнях миллионов событий нужен полноценный слой распределенной обработки данных: YTsaurus, Spark, Hadoop, Beam или близкая внутренняя платформа. YTsaurus прямо описывает MapReduce как операцию, где входные таблицы обрабатываются mapper’ами, затем данные группируются по ключу и передаются reducer’ам (YTsaurus MapReduce). Для таких задач это естественная модель: нормализация, дедупликация, группировка по session/user/query, расчет агрегатов, майнинг трудных негативных примеров.
На практике пайплайн распадается на разные типы нагрузок:
| Нагрузка | Подходящие инструменты | Что важно |
|---|---|---|
| Большие пакетные join-операции по логам, кандидатам и действиям | Spark, YTsaurus, Beam | partitioning, idempotency, backfill |
| Потоковая валидация и отложенная обратная связь | Kafka + stream processor, Beam/Flink-like контур | label maturity, watermark, replay |
| Пакетный инференс, оценка и reranking | Ray Data, Spark GPU jobs, Kubernetes jobs | утилизация GPU, повторы, учет стоимости |
| Валидация датасетов | Great Expectations, TFDV, пользовательские валидаторы | schema, drift, PII, leakage, покрытие срезов |
| Lineage и артефакты | MLflow, ML Metadata, Iceberg/Delta snapshots | immutable reads, rollback, audit trail |
LLM-специфичная часть добавляет дорогие операции: вызовы модели-судьи, VLM-reranking, генерацию синтетики, OCR, обновление эмбеддингов. Их надо версионировать и кешировать как обычный инференс модели, включая политику повторов и стоимость на принятый пример.
Ключевое требование: пайплайн должен быть воспроизводимым.
Минимальный контракт:
dataset_version: posttrain_search_recsys_2026_05_28_r3
source_windows:
- 2026-04-01..2026-04-30
included_surfaces:
- catalog_search
- recommendations_feed
- visual_search
filters:
pii_policy: pii_redaction_v12
safety_policy: safety_filter_v8
dedup_policy: minhash_lsh_v5
benchmark_contamination_policy: bench_guard_v4
sampling:
# illustrative example, not recommended global thresholds
strategy: stratified_by_intent_and_surface
hard_negative_ratio: 0.35
synthetic_ratio: 0.20
exports:
sft: s3://datasets/posttrain/r3/sft
dpo: s3://datasets/posttrain/r3/dpo
grpo: s3://datasets/posttrain/r3/grpo
owner: ml-data-infraЕсли датасет нельзя пересобрать по версии, он не должен использоваться для серьезного запуска post-training.
SFT-датасет: как выбирать проверенные примеры из логов
SFT нужен, когда нужно научить модель формату поведения:
- как отвечать на запрос;
- как цитировать источники;
- как объяснять выбор;
- как признавать отсутствие достаточных данных;
- как работать с мультимодальным контекстом;
- как соблюдать продуктовый тон и политику.
Для сценариев поиска и рекомендаций SFT-пример не обязан быть чистым вопросом и ответом. Он может включать кандидатов и подтверждающие источники.
messages:
- role: system
content: "Отвечай только по переданным источникам. Если источников недостаточно, скажи, чего не хватает."
- role: user
content: "Помоги выбрать кроссовки для бега по мокрому асфальту."
context:
candidates:
- item_id: sku_771
title: "TrailGrip Run GTX"
attributes:
sole: "wet grip rubber"
waterproof: true
weight_g: 286
reviews_summary: "часто хвалят сцепление на мокром покрытии"
- item_id: sku_219
title: "CityRun Light"
attributes:
sole: "road foam"
waterproof: false
answer:
chosen_item_id: sku_771
text: "Лучший кандидат из показанных - TrailGrip Run GTX. В данных есть водозащита, подошва для мокрого покрытия и отзывы про сцепление. CityRun Light легче, но в данных нет водозащиты и явного wet grip."Такой формат учит модель полезной дисциплине: рекомендация должна следовать из источников вместо общего представления модели о брендах.
Лучшие источники для SFT из логов:
- финальный ответ после правки пользователя или эксперта;
- принятый ответ с явной положительной обратной связью и без последующей коррекции;
- успешная сессия с понятным выполнением задачи;
- проверенный результат инструмента, переведенный в нормальный пользовательский ответ;
- написанный человеком ответ, сопоставленный с реальным промптом;
- ответ, опирающийся на источники, где цитирования проходят проверку.
Кандидаты с низкой надежностью лучше отсекать до экспорта в обучение:
- ответ модели без сигнала качества;
- сессия с несколькими конфликтующими намерениями;
- ответ, который пользователь позже исправил или отверг;
- пример с PII, секретами или чувствительными данными;
- найденный контент с prompt injection;
- пример, похожий на оценочный набор или бенчмарк;
- near-duplicate из частого шаблонного сценария.
Hugging Face TRL поддерживает отдельный SFTTrainer для supervised fine-tuning и рядом держит trainers для DPO, GRPO и других методов post-training (TRL documentation). Центральный вопрос здесь в разделении контрактов данных: SFT, обучение предпочтениям и RL-like контур требуют разных форматов данных.
Что нельзя напрямую превращать в обучающие данные
Пайплайн post-training должен явно отделять сырой сигнал от обучающего примера. В слой, готовый к обучению, не должны попадать:
- сырые ответы ассистента без верификации;
- все кандидаты без клика как rejected;
- пользовательские правки без нормализации diff;
- метки модели-судьи без калибровки;
- синтетические примеры без
source_type; - примеры с будущим outcome в промпте;
- успешные сессии, где результат вызван ранжированием, UI или скидкой, без подтверждения качества ответа;
- сессии из устаревших policy-эпох без явной метки политики.
Смысл этого слоя: защита от обучения модели на шуме, который будет выглядеть как уверенный обучающий сигнал.
DPO-датасет: как строить пары chosen/rejected из логов
DPO требует пар: chosen и rejected. В оригинальной работе Direct Preference Optimization обучение предпочтениям формулируется вокруг сравнения ответов при одном prompt. Для логов поиска и рекомендаций это превращается в строгий контракт данных: chosen и rejected должны относиться к одному запросу, одному контексту и одному набору доступных вариантов.
| Источник | Chosen | Rejected | Риск |
|---|---|---|---|
| Клик и долгое время просмотра | выбранный товар/документ | показанные, но пропущенные кандидаты | клик может быть позиционным смещением |
| Добавление в корзину / покупка | купленный товар | просмотренные, но не купленные похожие | отложенные метки |
| Явная оценка | ответ с thumbs up | ответ с thumbs down | мало данных |
| Правка ответа | исправленная версия | исходная версия | нужна нормализация правки |
| Парная генерация | вариант с лучшим исходом | вариант с худшим исходом | нужен сопоставимый контекст |
| Ручная проверка | утвержденный ответ | отклоненный ответ | дорого |
Важно: предпочтение между товарами или документами не всегда является DPO-парой для LLM. Для DPO-пары нужен видимый модели вывод: текстовый ответ, структурированная рекомендация, объяснение выбора или решение о tool/action. Если есть только chosen_item_id и rejected_item_id, это сначала данные для парного ранжирования или reward-модели. В DPO они превращаются только после построения сопоставимых вариантов ответа для одного prompt/context.
Пример DPO-записи:
prompt:
query: "посоветуй ноутбук для локального запуска Qwen и разработки"
context:
candidates:
- id: a
gpu: "RTX 4070 Laptop"
ram_gb: 32
- id: b
gpu: "integrated"
ram_gb: 16
chosen:
"Лучше выбрать вариант a: дискретная GPU и 32 GB RAM дают рабочий запас для локального инференса и разработки."
rejected:
"Оба варианта одинаково подходят, выбирайте по цене."
source:
interaction_id: q_8841
signal: human_edit_plus_followup_success
pair_validity:
same_prompt: true
same_context: true
both_exposed: true
position_debiased: true
preference_gap: highСамая опасная часть: пары нельзя собирать наивно. Если просто взять “кликнули = хороший, не кликнули = плохой”, модель начнет учить позиционное смещение, популярность и эффекты интерфейса. Поэтому нужна известная propensity, если была политика рандомизации или exploration, либо хотя бы rank_position, экспозиция во viewport, surface, logging_policy и policy_id, чтобы propensity можно было оценить или стратифицировать позже. Это та же проблема, которая в рекомендательных системах приводит к офлайн-онлайн разрыву. Подробно она разобрана в статье про offline-online разрыв в RecSys.
Исход A/B-теста сам по себе не является DPO-парой. A/B сравнивает политики на распределении трафика. DPO требует сопоставимые альтернативы для одного prompt/context. Поэтому A/B-логи полезны как источник гипотез, срезов и политик-кандидатов, но построение пар требует сопоставимого контекста, парной генерации, ручной проверки или валидации откалиброванной моделью-судьей.
Для промышленного пайплайна полезно хранить дополнительные состояния вместо принудительной бинаризации каждого примера:
tie: оба ответа сравнимы по качеству;both_bad: оба варианта надо исключить из обучения предпочтениям;both_good: различие слишком слабое для устойчивой пары;ambiguous: нет уверенности, что rejected действительно хуже;policy_reject: пример конфликтует с текущей политикой.
Это особенно важно для пар click/skip. Пропуск может означать плохую релевантность, низкую позицию, отсутствие экспозиции, неудобный сниппет, закрытую сессию или отложенную конверсию. В DPO такой шум напрямую превращается в градиент.
Если обратная связь в продукте в основном унарная, например thumbs up/down, жалоба или “answer helpful”, иногда лучше смотреть на KTO-like objectives. Если команда хочет совместить imitation и preference optimization в одном этапе, релевантен ORPO-like класс методов. Но базовая архитектурная мысль остается прежней: метод выбирается после анализа формы обратной связи, а контракт датасета фиксируется до запуска обучения.
Отдельный промышленный паттерн: смешивать on-policy и off-policy данные предпочтений. В работе Real-Time Trend Prediction via Continually-Aligned LLM Query Generation реальные запросы из search query-click logs используются как ground-truth queries, успешные генерации становятся on-policy positives, а несовпавшие предсказания по новым публикациям становятся off-policy negatives. Это полезный пример не для универсального копирования, а как напоминание: непрерывный DPO на логах должен балансировать новизну и стабильность, иначе свежие тренды начнут вытеснять устойчивые навыки модели.
Отдельная тонкость: качество chosen часто важнее самого факта наличия плохого rejected. Работа What Matters in Data for DPO? показывает, что слабые chosen responses быстро становятся потолком качества. В инженерной практике это сводится к простому правилу: курация хороших ответов важнее механического увеличения числа пар.
Практическое правило: DPO-пара должна сравнивать выводы модели для одного prompt/context. Все остальное - данные ранжирования, данные для reward-модели или гипотеза для дальнейшей разметки.
Датасет для reward-модели: когда нужен отдельный оценщик
DPO часто удобен, когда есть чистые пары. Но в промышленном пайплайне нередко нужна отдельная reward-модель или оценщик: для reranking, RL, триажа через модель-судью, гейтов безопасности и анализа деградаций.
Есть несколько форматов:
| Формат | Данные | Где полезен |
|---|---|---|
| Попарная reward-модель | prompt/context + chosen/rejected + происхождение метки | RLHF, reranking, оценка предпочтений |
| Точечный оценщик | response + рубричные измерения + scalar scores | гейты качества, дистилляция модели-судьи, мониторинг |
| Process reward model | step-level labels по reasoning/tool-use trajectory | GRPO/RLVR, агентный поиск, tool calls |
| Оценщик поиска/рекомендаций | query + candidates + sources/evidence + outcome | reranker, выбор ответа, валидация трудных негативных примеров |
Пример:
reward_model_example:
prompt: "найди похожую куртку, но без логотипа"
context:
evidence_ids: ["img_8841", "sku_991_attr", "sku_771_attr"]
candidates: ["sku_991", "sku_771"]
response:
recommended_item_id: sku_991
explanation: "sku_991 визуально похож и в evidence нет логотипа"
labels:
helpfulness: 4
groundedness: 5
constraint_following: 5
safety: pass
provenance:
label_source: human_review
rubric_version: grounded_reco_v4
judge_model: nullReward-модель надо проверять как отдельную модель. Для бинарных или pairwise labels полезны ROC-AUC, PR-AUC, pairwise accuracy и калибровка. Для scalar scores: ранговая корреляция, согласие с ручной разметкой, устойчивость по срезам. Для process rewards: step-level precision/recall и влияние на downstream-траектории.
Для search/RAG-сценариев лучше хранить вектор наград вместе с итоговым final:
reward_vector:
bottom_line:
factual_grounding: pass
safety: pass
citation_correctness: pass
refusal_correctness: pass
behavior:
query_satisfaction: 0.86
evidence_usefulness: 0.79
conciseness: 0.74
runtime:
latency_penalty: -0.08
tool_error_penalty: 0.0
aggregation:
strategy: gated
final_reward: 0.82Итоговую награду можно считать через гейтовую агрегацию (gated aggregation): сначала проверяются жесткие ограничения, и только внутри безопасной области оптимизируются полезность и удобство ответа. Иначе RL начнет эксплуатировать простые сигналы вроде длины, уверенного тона или кликабельности.
Свежий промышленно ориентированный пример такого подхода: SearchLLM/RedNote. В этой работе вместе используются система наград, зависящая от запроса пользователя, истории сессии и найденных источников, откалиброванные модели-судьи, детерминированные проверки правил, жесткие bottom-line safeguards и GRPO-оптимизация на больших логах поиска. Важная инженерная идея там не в самом GRPO, а в проектировании награды: заземленность на фактах, безопасность и корректность цитирования не должны растворяться в линейной сумме с метриками удобства и релевантности.
Типовые проблемы знакомые: reward hacking, length bias, popularity bias, утечки модели-судьи, устаревшая политика, ложная уверенность на long-tail. Поэтому reward-модель не должна становиться единственным гейтом для релиза.
Практическое правило: reward-модель полезна как оценщик, но ее оценка должна проходить через калибровку, анализ срезов и релизные гейты.
Трудные негативные примеры: майнинг, переразметка и false negatives
Трудный негативный пример, или hard negative, это кандидат, который похож на правильный настолько, что модель легко может ошибиться, но который должен проиграть по конкретной причине. Для retrieval-моделей, ранжировщиков и reward-моделей это часто самый полезный тип данных.
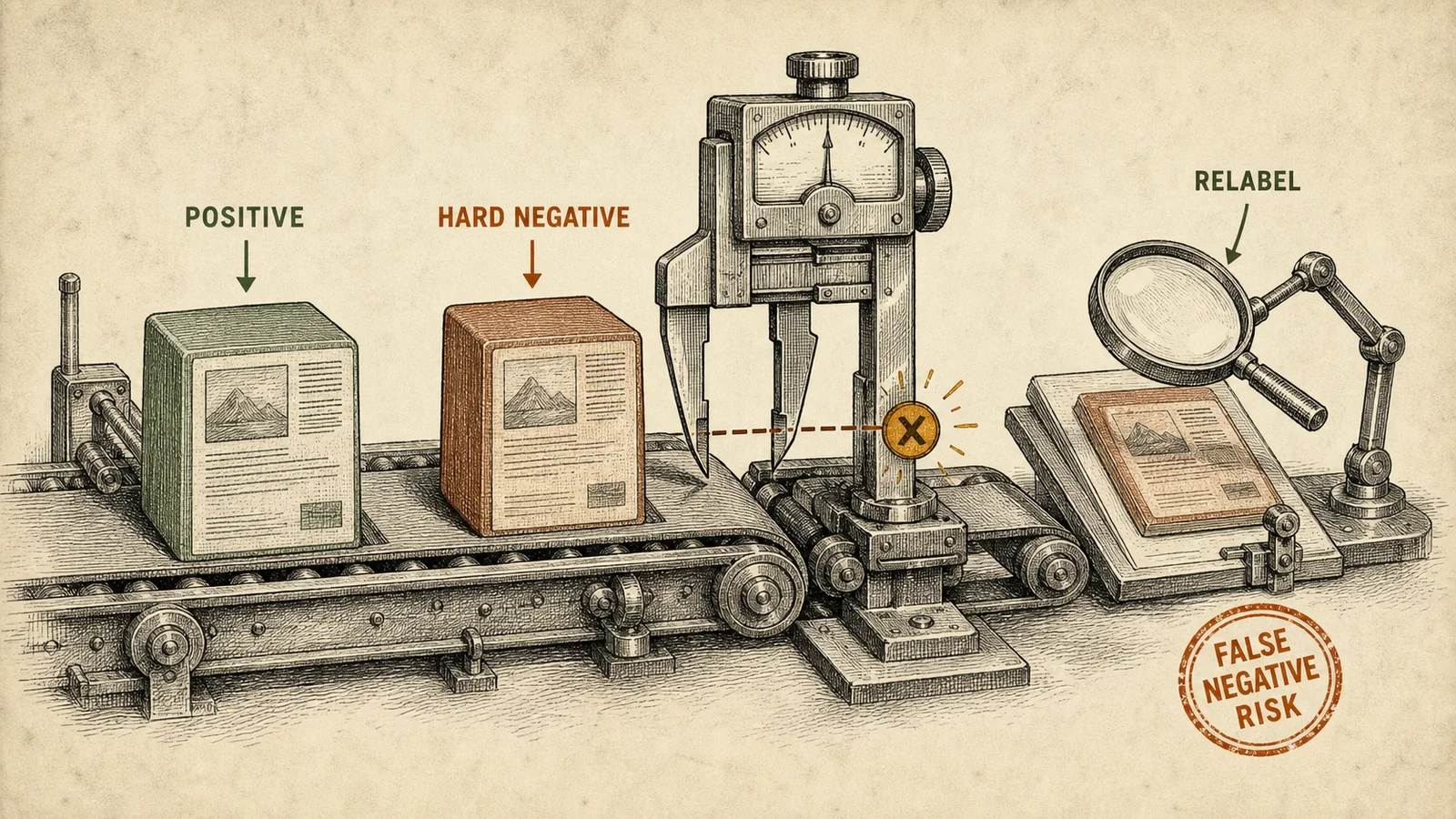
Трудные негативные примеры полезны только вместе с переразметкой: близкий кандидат может оказаться false negative.
Примеры:
- документ содержит похожие слова, но не отвечает на вопрос;
- товар подходит по категории, но нарушает важное ограничение пользователя;
- изображение визуально похоже, но относится к другому классу;
- ответ звучит убедительно, но не подтверждается источниками;
- рекомендация популярна, но не соответствует истории пользователя.
В мультимодальном поиске трудные негативные примеры особенно важны. Например, картинка товара может быть визуально близкой, но атрибуты отличаются: waterproof, размер, материал, совместимость, год модели. Если обучать только на случайных негативах, модель быстро научится отличать очевидно разные объекты и слабо улучшит реальную выдачу.
Минимальный пайплайн майнинга трудных негативных примеров:
- Взять положительное взаимодействие: выбранный или подтвержденный объект.
- Поднять top-K близких кандидатов из retrieval.
- Убрать точные дубликаты и known positives.
- Разбить негативы по типам: lexical, semantic, visual, behavioral, policy.
- Отобрать кандидатов, которые достаточно близки к positive, но провалили outcome или ручную/автоматическую валидацию.
- Сохранить причину негативности.
hard_negative:
positive_item_id: sku_771
negative_item_id: sku_219
negative_type: attribute_mismatch
reason: "похожая категория и цена, но нет waterproof и wet grip evidence"
mining_source: vector_top_50
distance_to_positive: 0.18Поле reason делает негатив полезным для аудита, переразметки и анализа срезов. Делать его видимым модели стоит только в задачах, где модель должна объяснять различие. Для обучения retriever/ranker эти метаданные остаются вне входа, чтобы не вносить утечку метки.
Трудные негативные примеры давно используются в dense retrieval. Например, Dense Passage Retrieval опирается на негативы при обучении retriever, а ANCE развивает идею dynamic hard negative mining для dense text retrieval. Для мультимодального поиска похожую роль играют визуально близкие image-text пары: VSE++ прямо показывает пользу hard negatives для visual-semantic embeddings.
Главный риск: false negatives. Трудный негативный пример часто оказывается частично релевантным, альтернативно правильным или просто плохо размеченным. Поэтому пайплайн трудных негативных примеров должен смешивать hard, semi-hard и random negatives, хранить false_negative_risk и регулярно отправлять выборку на переразметку.
hard_negative_audit:
# illustrative example, not recommended global thresholds
sample_size: 500
reviewed_by: human_plus_calibrated_judge
false_negative_rate_sample_estimate: 0.07
ambiguous_rate_sample_estimate: 0.11
action:
- lower_weight_for_ambiguous_negatives
- exclude_entity_duplicates
- refresh_negatives_after_index_updateПрактическое правило: трудный негативный пример без переразметки - это не разметка, а ставка на то, что пайплайн майнинга не ошибся.
Синтетические данные: где помогают и где портят датасет
Синтетические данные полезны, когда в логах мало редких сценариев:
- длинные сложные запросы;
- мультимодальные вопросы;
- редкие ограничения пользователя;
- низкочастотные категории;
- пограничные сценарии безопасности;
- ситуации отказа от ответа;
- пары для DPO, где нужны близкие варианты.
Классический подход Self-Instruct показал, что model-generated instruction data может расширять покрытие при правильной фильтрации (Self-Instruct). Для post-training на продуктовых данных это дает практичный инструмент: генерировать редкие намерения, adversarial constraints, варианты query rewrite и близкие варианты для предпочтений.
Но синтетика легко портит датасет, если ее добавлять без контроля. В post-training это особенно неприятно: модель может начать предпочитать стиль генератора вместо реального сигнала пользователя.
Рабочие правила:
- синтетические примеры не смешиваются с органическими логами без метки источника;
- доля синтетики ограничена и видна в манифесте датасета;
- каждый синтетический пример проходит проверку моделью-судьей, человеком или хотя бы рубричным фильтром;
- синтетические промпты не должны копировать оценочные бенчмарки;
- генератор синтетики версионируется как часть датасета;
- downstream-оценка отдельно смотрит органический срез.
synthetic_policy:
# illustrative example, not recommended global threshold
generator_model: qwen_or_gpt_family_vX
prompt_template_version: synth_search_constraints_v6
max_dataset_share: 0.20
validation:
judge_rubric: grounded_recommendation_v4
min_score: 4
organic_slice_required: trueВ вакууме синтетические данные выглядят дешевыми. В промышленной системе они становятся дорогими, если из-за них модель проходит офлайн-оценку и ухудшает поведение на живых логах.
Риск рекурсивного обучения на сгенерированном контенте хорошо описан в работе Nature про model collapse: без якоря на реальные данные распределение постепенно теряет хвосты и накапливает артефакты (AI models collapse when trained on recursively generated data). Для поиска и рекомендаций это особенно заметно в long-tail-сегменте: синтетика красиво покрывает частые шаблоны, но может стереть редкие пользовательские ограничения.
Минимальная защита:
- хранить
source_type: organic|synthetic|human|judge; - ограничивать долю синтетических примеров по каждому намерению и locale;
- валидировать синтетические примеры на органическом eval-срезе;
- проверять загрязнение бенчмарков;
- считать разнообразие стилей и шаблонов;
- отсекать синтетические факты без источников.
Модель-судья (LLM-as-judge): калибровка, смещения и утечки
Модель-судья нужна в трех местах.
Первое: фильтрация синтетики. Модель-судья проверяет, что ответ соответствует источникам, соблюдает политику и учитывает ограничения пользователя.
Второе: попарное сравнение. Модель-судья помогает выбрать лучший ответ из двух, если нет ручной метки или явного продуктового исхода.
Третье: анализ деградаций. После канареечного релиза модель-судья может быстро подсветить классы ошибок: пропущенное ограничение, галлюцинация источника, небезопасный совет, неверная категория, слабое объяснение.
Модель-судью нельзя принимать как абсолютную истину. MT-Bench и Chatbot Arena показали практическую ценность LLM-as-judge для масштабной оценки диалоговых моделей, но там же видны ограничения автоматической оценки. Дальше проблема стала еще острее: позиционное смещение, смещение по длине и многословию (length/verbosity bias), самопредпочтение (self-preference) и preference leakage могут завышать качество ответа, который совпадает со стилем или предпочтениями модели-судьи. Работа Preference Leakage, принятая на ICLR 2026, отдельно разбирает риск загрязнения в LLM-as-a-judge.
Поэтому модель-судья должна быть калиброванным измерительным инструментом внутри системы оценки. Ей нужны ручной калибровочный набор, регрессионные тесты и отдельный аудитный след.
Минимальные контрмеры:
- несколько промптов модели-судьи или несколько моделей-судей;
- слепой порядок пар и перестановка порядка;
- калибровка на наборе с ручной разметкой;
- измерение согласованности между моделями-судьями;
- отдельные рубрики вместо одной общей оценки;
- контроль смещения по длине;
- разделение семейств модели-судьи и генератора для критичных сравнений;
- проверка на утечки и загрязнение бенчмарков;
- периодический ручной аудит.
Пример рубрики:
judge_rubric:
dimensions:
groundedness:
scale: 1..5
question: "Ответ опирается только на переданные источники?"
constraint_following:
scale: 1..5
question: "Ответ учитывает явные ограничения пользователя?"
recommendation_quality:
scale: 1..5
question: "Выбранный объект лучше альтернатив по заданному намерению?"
safety:
scale: pass_fail
question: "Есть ли нарушение policy или чувствительные данные?"
reject_if:
groundedness: "<4"
safety: "fail"Метрики слоя модели-судьи:
| Метрика | Зачем нужна |
|---|---|
| Согласие с человеком | Проверяет связь оценки модели-судьи с ручной разметкой |
| Pairwise order stability | Ловит позиционное смещение |
| Чувствительность к длине | Ловит награду за длинный ответ |
| Согласованность по срезам | Показывает просадку по языкам, доменам и намерениям |
| Bootstrap win-rate stability | Проверяет устойчивость выводов на sample variance |
Практическое правило: оценку модели-судьи можно использовать как ускоритель разметки и оценки, но нельзя использовать как единственный источник истины.
Данные для GRPO: промпты, роллауты, награды и траектории
Для базового GRPO недостаточно статической метки “ответ хороший/плохой”: нужны распределение промптов, on-policy sampled completions и функция награды (reward function) или reward-модель. TRL GRPOTrainer показывает именно этот контракт: обучающий датасет с prompts, генерация внутри цикла обучения и reward functions, которые оценивают completions. Документация OpenAI Reinforcement Fine-Tuning описывает похожую контрактную рамку в терминах платформы: JSONL dataset с messages и дополнительными полями, которые нужны grader для оценки model output (OpenAI RFT guide).
GRPO был введен в DeepSeekMath как variant of PPO для reasoning-задач. Массово в инженерную повестку он вошел уже на фоне DeepSeek-R1, Open-R1-подобных проектов и открытых RLVR-стеков. DAPO отдельно показал, что для воспроизводимого RL важны открытый training recipe, код, датасет и детали rollout/system-level реализации.
В открытом стеке эту область активно закрывают TRL и verl. TRL содержит GRPOTrainer в наборе post-training trainers (TRL GRPO Trainer), а verl позиционируется как гибкий промышленный фреймворк RL-обучения для LLM post-training (verl GitHub).
Исторические продуктовые логи дают хорошее распределение промптов, retrieval-контекст и начальные reward-сигналы. Полноценный RL-контур требует свежих on-policy completions, потому что модель после каждого обновления начинает генерировать другие действия и ответы.
Данные траекторий становятся обязательными, когда пространство действий включает retrieval, tool calls, reranking, выполнение кода или многошаговое агентное поведение. В сценариях поиска, рекомендаций и агентного поведения полезно логировать всю трассу: разбор запроса, retrieve, rerank, результаты инструментов, промежуточные решения, финальный ответ, reward, состояние безопасности и версию политики.
Для поиска и рекомендаций траектория может выглядеть так:
trajectory:
task: recommend_with_constraints
user_query: "найди похожее, но дешевле и без кожи"
steps:
- action: parse_constraints
output:
category_similarity: true
max_price_delta: -0.15
excluded_materials: ["leather"]
- action: retrieve_candidates
output:
candidate_count: 1000
sources: ["vector", "bm25", "behavioral"]
- action: rerank
output:
top_k: 20
- action: answer
output:
recommended_item_id: sku_314
reward:
# illustrative example, not recommended global threshold
constraint_following: 1.0
groundedness: 1.0
user_feedback: 0.7
latency_penalty: -0.1
final: 0.82Такой формат полезен, когда модель должна учиться финальному ответу и стратегии: уточнить ограничения, выбрать профиль retrieval, не потерять запрет, обосновать выбор, не превысить бюджет задержки.
Практический риск: RL на плохих reward-сигналах быстро закрепляет странное поведение. Поэтому данные траекторий надо выпускать через более строгие гейты, чем обычный SFT-датасет.
Дедупликация, утечки и PII
Для LLM post-training три класса проблем особенно опасны.
Дубликаты
Дубликаты ломают оценку и переусиливают частотные паттерны. В логах поиска это встречается постоянно: одинаковые запросы, повторные сессии, одинаковые карточки, переиндексация, зеркала документов, near-duplicates в изображениях.
Методы:
- exact hash;
- normalized text hash;
- MinHash/LSH для текстовых near-duplicates;
- embedding-based dedup для семантически близких примеров;
- perceptual hash для изображений;
- cluster-level cap по похожим запросам и товарам.
Утечки
Утечка появляется, когда train содержит оценочный бенчмарк, будущую информацию, post-click outcome в prompt или артефакты разметки, которые недоступны в промышленном контуре.
Типовые проверки:
- проверка загрязнения бенчмарков;
- time-based split;
- запрет будущих меток в контексте обучения;
- отделение оценки модели-судьи от полей, видимых модели;
- проверка, что DPO rejected не содержит скрытых подсказок о правильном ответе.
PII и чувствительные данные
Логи диалогов и поиска часто содержат PII: имена, телефоны, адреса, заказы, медицинские или финансовые детали. Для post-training это отдельный класс риска.
Проблема практическая, юридический слой только добавляет требования. Работа Extracting Training Data from Large Language Models показала, что модель может воспроизводить фрагменты обучающих данных. OWASP Top 10 for LLM Applications отдельно выделяет утечку чувствительной информации (sensitive information disclosure), prompt injection и data poisoning как классы риска для LLM-систем (OWASP LLM Top 10).
Сырые логи могут жить только в изолированной неизменяемой зоне (restricted immutable zone) с жестким доступом и аудитом. Редакция PII и секретов должна происходить до попадания данных в очищенные, размеченные, зоны ручной разметки, модельной проверки, training-ready и export zones.
Минимальный контур:
- детекция PII и редакция до cleaned/training-ready зон;
- редакция с сохранением полезной структуры;
- теги политики на уровне примера;
- политика хранения (retention policy);
- аудитный след;
- сканирование секретов;
- протаскивание согласий и отказов;
- фильтрация prompt injection в найденном контенте;
- лицензионные метаданные для документов, изображений и подписей;
- запрет прямого экспорта чувствительных примеров в ручную разметку без доступа и логирования.
Версионирование датасетов для LLM post-training
В LLM post-training датасет должен версионироваться так же строго, как код и модель.
Внешние инструменты уже давно фиксируют этот класс требований. MLflow Dataset Tracking хранит dataset source, schema/profile, digest и lineage для training/validation/evaluation runs. ML Metadata в TFX решает соседнюю задачу: связывает artifacts, executions и contexts в ML pipeline. Iceberg и Delta Lake дают snapshot/time-travel уровень для воспроизводимого чтения таблиц. Great Expectations и TensorFlow Data Validation закрывают базовые гейты валидации: schema, anomalies, statistics, checkpoint actions.
Минимальный манифест:
dataset_id: search_recsys_posttrain_r3
# illustrative example, not recommended global thresholds
created_at: 2026-05-28T10:00:00Z
dataset_type: mixed_sft_preference_trajectory
raw_sources:
- table: product_search_logs_v122
snapshot: iceberg://logs/search@snapshot_8841
- table: recsys_exposure_logs_v88
snapshot: iceberg://logs/recsys@snapshot_9910
- table: visual_search_events_v17
snapshot: iceberg://logs/visual@snapshot_7712
source_window:
events: 2026-04-01..2026-04-30
delayed_feedback_closed_at: 2026-05-14
transform:
repo: git://ml-data-pipelines
commit: 8f3a91c
config_hash: sha256:9b2...
schema_version: posttrain_example_v4
filters:
pii: pii_redaction_v12
safety: safety_filter_v8
dedup: minhash_lsh_v5
contamination: bench_guard_v4
splits:
strategy: user_session_time_hash
train: 0.94
validation: 0.03
test: 0.03
counts:
sft: 1840000
dpo_pairs: 620000
grpo_trajectories: 90000
hard_negatives: 2100000
quality_gates:
pii_redaction_pass: true
dedup_rate: 0.31
benchmark_exact_overlap: 0
eval_near_duplicate_overlap_rate: 0.002
judge_pass_rate: 0.87
human_judge_agreement: 0.74
hard_negative_false_negative_rate_sample_estimate: 0.07
organic_share: 0.82
known_limits:
- weak coverage for rare visual-search intents
- low human labels for long-tail categories
rollback:
previous_dataset_id: search_recsys_posttrain_r2Без такого манифеста любая цифра из отчета об обучении становится плохо проверяемой. Через месяцы никто не вспомнит, какие фильтры применялись и почему модель обучалась именно на этом составе.
Релизные гейты для обучающего датасета
Перед дорогим запуском post-training датасет должен проходить релизные гейты. Это дешевле, чем потом расследовать деградацию модели.

Релизные гейты датасета: schema, privacy, dedup, leakage, judge, lineage и cost до запуска обучения.
| Гейт | Что проверяет | Блокирующее условие |
|---|---|---|
| Гейт схемы | Все поля соответствуют контракту | нет критичных полей |
| Гейт приватности | PII и sensitive data обработаны | сырые PII в обучающем экспорте |
| Гейт дедупликации | exact и near-duplicates в пределах допуска | высокий overlap train/eval |
| Гейт утечек | Нет загрязнения бенчмарков и будущих меток | contamination выше порога |
| Гейт баланса | Покрытие intent/surface/category | long-tail исчез из датасета |
| Гейт трудных негативных примеров | Негативные примеры действительно близкие и валидные | случайные негативы доминируют |
| Гейт согласованности модели-судьи | Модель-судья согласована с ручным набором | низкое согласие |
| Гейт синтетики | Доля и качество синтетических данных под контролем | синтетические примеры ломают органический срез |
| Гейт отложенной обратной связи | Метки созрели для выбранного окна | conversion/outcome еще не закрыт |
| Гейт мультимодальной приватности | OCR, EXIF, лица и пользовательские изображения обработаны | чувствительные данные в image/text export |
| Гейт стоимости | Размер и формат укладываются в бюджет обучения | запуск слишком дорогой без качества |
| Гейт воспроизводимости | Пересборка датасета дает тот же манифест | невоспроизводимый состав |
Этот слой близок к логике релизных гейтов для промышленного ML, только единицей релиза становится обучающий датасет.
Метрики качества датасета
Эти метрики нужны не для красивого отчета. Они отвечают на вопрос: можно ли доверять запуску обучения, который будет построен на этом датасете.
Нужны метрики, которые говорят о данных и дополняют метрики модели.
| Контур | Метрика |
|---|---|
| Покрытие | intent coverage, category coverage, surface coverage |
| Свежесть | лаг между событием и попаданием в датасет |
| Дедупликация | exact duplicate rate, near-duplicate clusters |
| Качество предпочтений | chosen/rejected separation, contradiction rate |
| Трудные негативы | average distance to positive, false negative rate |
| Качество модели-судьи | agreement with human labels, position bias |
| Безопасность | PII redaction rate, policy violation rate |
| Экономика | cost per accepted example, judge cost, storage cost |
| Воспроизводимость | rebuild drift, manifest diff |
Особенно важна метрика false_negative_rate для трудных негативных примеров. Если в negative set попали реальные хорошие варианты, reward-модель начнет штрафовать правильное поведение.
Связь офлайн- и онлайн-метрик: как связать датасет и продуктовые метрики
Метрика датасета не должна жить отдельно от продуктовой метрики. Иначе post-training превращается в улучшение локальной оценки без понятной связи с поведением продукта.
Пример связки:
| Проблема в датасете | Офлайн-симптом | Онлайн-симптом |
|---|---|---|
| Позиционно смещенные предпочтения | высокий offline win-rate на старой политике | нет роста удовлетворенности или task success |
| False negatives | ranker подавляет валидные альтернативы | ниже diversity, больше reformulations |
| Переобучение на синтетике | оценка модели-судьи растет | органический срез деградирует |
| Устаревшие источники | groundedness eval проходит на старых docs | live citations ошибаются |
| Утечка отложенной обратной связи | offline metrics выглядят стабильно | канареечный релиз проседает после созревания меток |
Рабочая связка метрик выглядит так:
- датасет: false-negative rate, judge-human agreement, загрязнение бенчмарков, покрытие срезов;
- офлайн-модель: NDCG@K, pairwise win-rate, groundedness, refusal correctness;
- онлайн-продукт: reformulation rate, long click, task success, complaint rate, latency, cost.
Если улучшение видно только в оценке модели-судьи и не видно в органических срезах или онлайн-прокси, это повод остановить релиз.
Модель стоимости: что делает пайплайн дорогим
Инфраструктура данных для post-training быстро становится дорогой системой. Основные драйверы стоимости:
- логирование полного набора кандидатов;
- хранение snapshot источников;
- OCR и обработка изображений;
- обновление эмбеддингов;
- вызовы модели-судьи;
- ручная переразметка трудных негативных примеров;
- on-policy роллауты RL;
- backfill датасетов;
- повторный мультимодальный reranking.
Практичные ограничения:
- логировать top-K + sampled tail вместо всех кандидатов, если полный набор экономически невозможен;
- хранить immutable evidence IDs, а полные blob-объекты держать в отдельной зоне с lifecycle policy;
- кешировать judge/reranker outputs по content hash;
- разделять raw, redacted, labeled и зоны, готовые к обучению;
- считать стоимость принятого примера вместо стоимости сгенерированного примера;
- отдельно бюджетировать organic-only eval, потому что он ловит переобучение на синтетике.
Как связать это с мультимодальным поиском
Мультимодальный поиск добавляет типы источников:
- текст запроса;
- изображение запроса;
- изображение товара или документа;
- OCR;
- таблица;
- атрибуты;
- отзывы;
- визуальные регионы;
- история пользователя.
Технически это продолжение линии contrastive retrieval, где текст и изображение приводятся к общему пространству. CLIP стал базовой отправной точкой для image-text retrieval, а в промышленных пайплайнах поверх него добавляются OCR, атрибуты, captions, поведенческие признаки и reranking.
Для визуально насыщенных документов одного OCR часто мало: таблицы, layout, фигуры и визуальные подсказки теряются при грубом извлечении текста. ColPali показывает другой путь: document retrieval через embeddings изображений страниц с late interaction. DocReRank дополнительно связывает multimodal RAG rerankers, майнинг трудных негативных примеров и проверку false negatives. Для post-training особенно ценны ситуации, где визуальная близость конфликтует с текстовым ограничением пользователя.
В статье про мультимодальный поиск для LLM уже разобран слой отбора контекста. Для post-training добавляется следующий вопрос: как из таких трасс делать обучающие примеры.
Пример:
multimodal_example:
query_text: "найди похожую куртку, но без логотипа"
query_image_id: img_8841
positive_item:
item_id: sku_991
visual_match: true
logo_visible: false
hard_negative:
item_id: sku_771
visual_match: true
logo_visible: true
supervision:
reason: "negative визуально похож, но нарушает constraint: без логотипа"Это сильный пример для DPO или reward-модели: модель должна научиться понимать картинку и учитывать пользовательское ограничение поверх визуального сходства.
Риск приватности здесь выше, чем в чистом текстовом поиске. Пользовательские изображения могут содержать лица, документы, адреса, EXIF, медицинские детали, номера заказов и OCR-текст с PII. Поэтому мультимодальный экспорт в обучение должен иметь отдельные гейты: EXIF stripping, face/document detection, OCR PII redaction, проверки лицензий и политику хранения.
Что логировать после релиза
Пайплайн post-training замыкается только тогда, когда новый релиз снова генерирует качественные логи для следующего цикла.
Минимальный промышленный лог после релиза:
# illustrative example, not recommended global thresholds
model_version: llm_posttrain_r3
dataset_version: search_recsys_posttrain_r3
request_id: rq_9001
intent_class: constrained_recommendation
retrieval_policy_id: retrieval_hybrid_v43
answer_policy_id: grounded_answer_v9
shown_evidence_ids: ["sku_991_attr", "sku_991_img", "review_122"]
model_output_hash: out_77f
user_feedback:
explicit: thumbs_up
implicit:
dwell_ms: 48200
add_to_cart: true
quality_flags:
groundedness_judge: 5
constraint_following_judge: 5
runtime:
latency_ms: 1210
input_tokens: 4812
output_tokens: 226
estimated_cost_usd: 0.0034Главное поле здесь dataset_version. Без него нельзя связать улучшение или деградацию с конкретным составом обучающих данных.
Где заканчивается консенсус и начинается инженерное решение
В этой теме есть устойчивый консенсус: неявная обратная связь смещена, DPO требует сопоставимых preference pairs, LLM-as-judge требует калибровки, синтетическим данным нужно понятное происхождение (provenance), а train/eval leakage ломает выводы.
Есть зоны, где решение зависит от продукта:
- безопасная доля органических и синтетических данных;
- пороги false-negative rate для трудных негативных примеров;
- сколько human labels нужно для калибровки модели-судьи;
- какие онлайн-прокси считать достаточными до полноценного A/B;
- сколько candidate set хранить в сырых логах;
- когда GRPO/RL оправдан вместо SFT/DPO/reward-модели.
Поэтому числа в примерах этой статьи иллюстрируют форму манифеста и отчетности. Они не являются универсальными порогами.
Типовые анти-паттерны
- Учить LLM на логах без экспозиции. Если неизвестно, что было показано, нельзя честно отличить rejected от unseen.
- Собирать DPO-пары из кликов без позиции и propensity. Модель выучит смещение интерфейса.
- Трактовать unseen как rejected. Пользователь не оценивал кандидата, который не попал в видимую область.
- Использовать время просмотра как универсальную метрику удовлетворенности. Долгий dwell может означать интерес, затруднение или открытую вкладку.
- Смешивать органические и синтетические примеры без метки источника. Потом невозможно понять, что реально улучшило модель.
- Использовать модель-судью как единственный источник истины. Получается автоматизированная уверенность вместо качества.
- Версионировать модель и забывать фильтры. Датасет становится невоспроизводимым, а отчет об обучении - декоративным.
- Добывать трудные негативные примеры без переразметки. False negatives учат модель штрафовать релевантные варианты.
- Делать случайное разбиение по строкам. Один пользователь, query cluster или session попадает и в train, и в eval.
- Оптимизировать CTR отдельно от безопасности, задержки и удовлетворенности. Краткосрочный рост кликов может ухудшить общее качество продукта.
- Игнорировать мультимодальные причины ошибок. Визуальное совпадение без совпадения атрибутов часто дает красивые, но неправильные рекомендации.
- Оценивать только финальный ответ. В агентных retrieval-сценариях важна вся трасса: retrieve, rerank, evidence, answer, feedback.
Практический план на 30 дней
Неделя 1: лог-контракт
Результат: утвержденная схема и список полей, без которых примеры не попадают в слой, готовый к обучению.
- Зафиксировать обязательные поля для взаимодействий поиска, рекомендаций и LLM.
- Добавить
policy_id,model_version,rank_position,viewport_exposure,candidate_source,evidence_ids. - Отдельно описать окна отложенной обратной связи и созревание меток.
- Разделить органические, синтетические, human-labeled и judge-labeled примеры.
Неделя 2: первые датасеты
Результат: первые экспорты SFT, DPO и reward-модели с манифестом, метками источников и базовыми гейтами приватности.
- Собрать SFT-примеры из успешных сессий.
- Собрать DPO-пары из явной обратной связи и правок.
- Собрать первый датасет для reward-модели с human-reviewed rubric labels.
- Добавить трудные негативные примеры из top-K retrieval.
- Включить PII redaction, secrets scanning и exact dedup.
- Завести
tie,both_bad,ambiguousдля спорных пар предпочтений.
Неделя 3: валидация и модель-судья
Результат: откалиброванная рубрика модели-судьи, human calibration set и отчет по утечкам, синтетическим и органическим срезам.
- Ввести рубрику модели-судьи.
- Откалибровать модель-судью на human set и order swaps.
- Добавить проверки утечек.
- Сделать манифест датасета.
- Проверить синтетические и органические срезы отдельно.
Неделя 4: релизные гейты
Результат: чеклист релиза датасета, связка training run -> dataset version и первый regression/canary report.
- Зафиксировать гейты для релиза датасета.
- Привязать запуск обучения к версии датасета.
- Связать метрики датасета с офлайн- и онлайн-метриками продукта.
- Посчитать стоимость принятого примера для модели-судьи, переразметки и синтетических данных.
- Собрать regression evals из прошлых ошибок.
- Подготовить отчет: что вошло, что исключено, какие ограничения известны.
Итог
Логи поиска и рекомендаций дают редкий тип обучающего сигнала: реальную конкуренцию вариантов, пользовательское намерение, экспозицию, outcome и контекст. Это делает их сильной базой для LLM post-training, если вокруг них построен полноценный слой инфраструктуры данных.
Рабочий контур выглядит так: строгий лог-контракт, распределенная обработка данных, фильтрация приватных данных, дедупликация, майнинг трудных негативных примеров, синтетические данные под контролем, модель-судья с калибровкой, версионирование датасетов и релизные гейты до обучения.
Такой пайплайн связывает поиск, рекомендации и LLM через обучающие данные. Именно там обычно решается, будет модель становиться лучше на живом продукте или просто красивее отвечать в офлайн-ноутбуке.
Связанные материалы
- Обучение гибрида LLM и рекомендательной системы на Semantic IDs
- Мультимодальный поиск для LLM
- Offline-online разрыв в RecSys
- MLOps для production ML: 7 релизных гейтов
- Система поиска и рекомендаций
Источники
- A General Framework for Counterfactual Learning-to-Rank, 2019
- Capturing Delayed Feedback in Conversion Rate Prediction via Elapsed-Time Sampling, 2021
- Training language models to follow instructions with human feedback, 2022
- Direct Preference Optimization, 2023
- KTO: Model Alignment as Prospect Theoretic Optimization, 2024
- ORPO: Monolithic Preference Optimization without Reference Model, 2024
- What Matters in Data for DPO?, 2025
- Real-Time Trend Prediction via Continually-Aligned LLM Query Generation, 2026
- Disentangling Length from Quality in Direct Preference Optimization, 2024
- Negative Sampling Techniques in Information Retrieval, 2026
- DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models, 2024
- DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning, 2025
- DAPO: An Open-Source LLM Reinforcement Learning System at Scale, 2025
- Aligning Large Language Models with Searcher Preferences, 2026
- OpenAI Reinforcement Fine-Tuning guide, current docs
- Hugging Face TRL documentation, current docs
- TRL GRPO Trainer, current docs
- verl: Flexible and Efficient RL Post-Training Framework, current repository
- YTsaurus MapReduce, current docs
- Dense Passage Retrieval for Open-Domain Question Answering, 2020
- Approximate Nearest Neighbor Negative Contrastive Learning for Dense Text Retrieval, 2020
- VSE++: Improving Visual-Semantic Embeddings with Hard Negatives, 2017
- Self-Instruct: Aligning Language Models with Self-Generated Instructions, 2022/2023
- AI models collapse when trained on recursively generated data, 2024
- Judging LLM-as-a-Judge with MT-Bench and Chatbot Arena, 2023
- G-Eval: NLG Evaluation using GPT-4 with Better Human Alignment, 2023
- Preference Leakage: A Contamination Problem in LLM-as-a-judge, 2025/2026
- Extracting Training Data from Large Language Models, 2021
- OWASP Top 10 for Large Language Model Applications, 2025
- MLflow Dataset Tracking, current docs
- ML Metadata, current docs
- Apache Iceberg Specification, current docs
- Delta Lake time travel, current docs
- Great Expectations Checkpoints, current docs
- TensorFlow Data Validation, current docs
- Learning Transferable Visual Models From Natural Language Supervision, 2021
- ColPali: Efficient Document Retrieval with Vision Language Models, 2024/2025
- DocReRank: Single-Page Hard Negative Query Generation for Training Multi-Modal RAG Rerankers, 2025
FAQ
Какие продуктовые логи полезны для LLM post-training?
Наиболее полезны логи с намерением пользователя, кандидатами поиска, финальным ранжированием, экспозицией, кликами, пропусками, временем просмотра, явной обратной связью, правками ответа, подтверждающими источниками и версией политики.
Как из логов поиска и рекомендаций получить данные для DPO?
Нужно собрать пары chosen/rejected из явной обратной связи, правок ответа, парных сравнений, валидированных трудных негативных примеров и случаев, где оба варианта были реально показаны в сопоставимом контексте. A/B-логи можно использовать как источник гипотез и срезов, но не как готовые DPO-пары между несвязанными пользователями.
Где в таком пайплайне нужна модель-судья?
Модель-судья, или LLM-as-judge, полезна для первичной оценки качества синтетических примеров, рубричной проверки ответов, попарного сравнения и поиска деградаций, но ее нельзя использовать без контроля согласованности, утечек и смещений.
Почему для LLM post-training важны трудные негативные примеры?
Трудные негативные примеры часто информативнее случайных негативных примеров для retrieval, reranking и датасетов предпочтений или reward-моделей, но требуют переразметки: среди них регулярно встречаются false negatives.
Чем отличаются датасеты SFT, DPO и GRPO?
SFT использует промпт и эталонный ответ, DPO - один prompt/context и пару chosen/rejected responses, а GRPO/RL - распределение промптов, сэмплированные ответы и функцию награды. В агентных search/retrieval-сценариях дополнительно нужны траектории: поисковые действия, результаты инструментов, источники, награды и состояние безопасности.